My Thoughts
Short-form commentary on macro, market structure, commodities, Bitcoin, crypto markets, and AI.

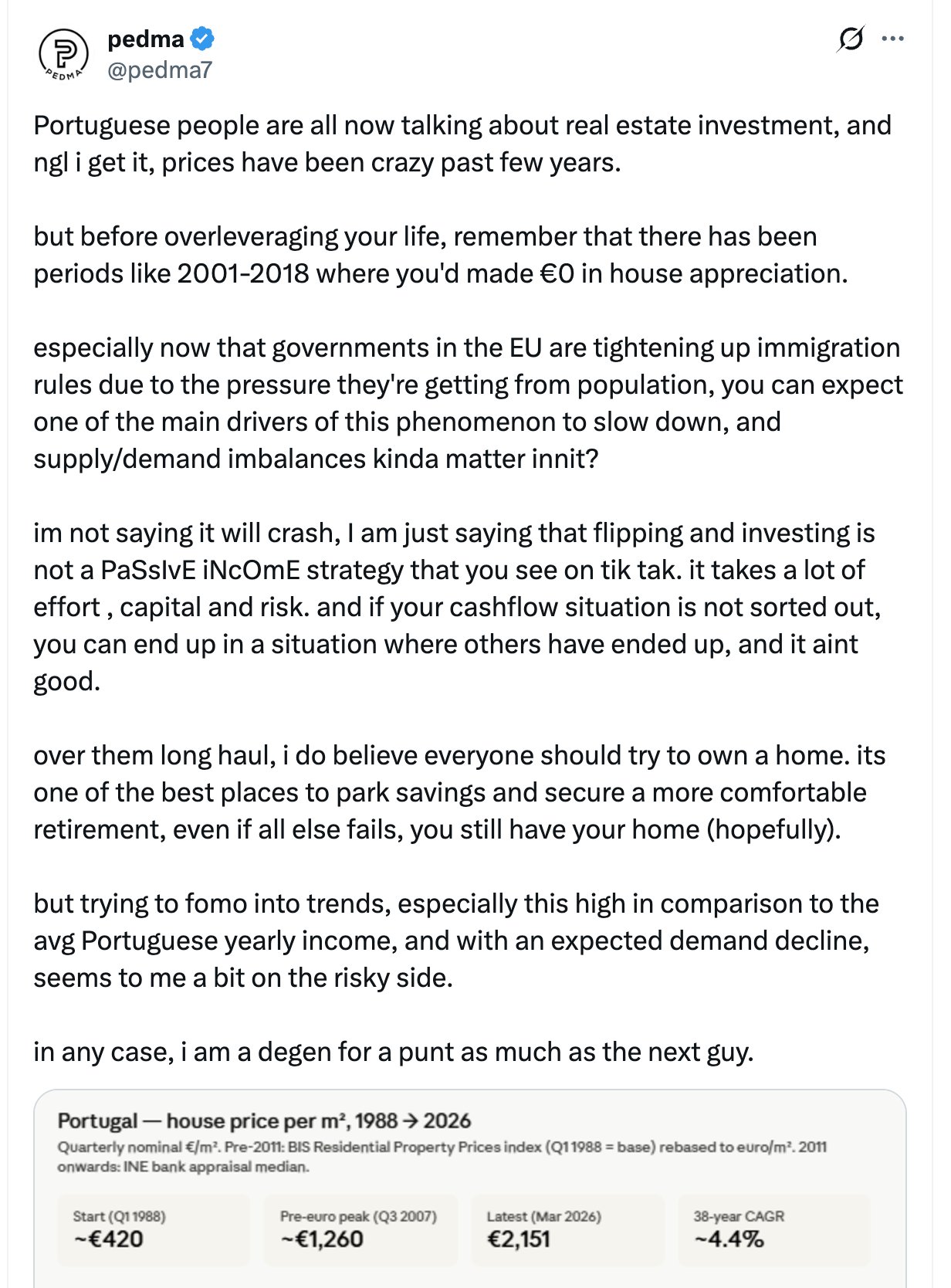
Portugal Real Estate: Credit, Not Immigration Drives The Prices Up
I frequently come across articles that blame mainly immigration for the steep price increase of dwellings in Portugal. While emigration creates more demand for housing and drives the prices up, it’s far from the main factor responsible for appreciation of real estate in Portugal. Given this, it is also equally incorrect to claim that the Portuguese real estate markets relies mainly on immigrants to support the price.
A better way would be looking at interest rates and availability/liquidity of credit. Portugal has very accessible/low mortgage rates, and you can borrow close to EURIBOR as a business. The cost, availability of credit and real estate market liquidity/size (e.g. think of total transaction volume, market depth) have a steeper effect on prices much more than all immigration combined.
ECB kept deposit facility rate at zero or negative, for close to decade (main refinancing operation and marginal lending facility rates were also kept low during that period). It wasn't only the ECB -- Fed, BoJ, PBoC had similar policies. During that period, a lot of debt/credit flowed into the Eurozone, a lot of it seeking real estate investments. Portugal has a quite small market, small GDP, so it's easier to bid up the yield with the new credit. If you look across the EU, you'll see that real estate rose in price everywhere, not just in Lusitânia.
Also, it may be quite irrelevant if the real estate prices crash for some period of time. As long as the rents cover the debt service, real estate owners will continue in profit. This is the basis of many structured real estate investment vehicles.
A much bigger risk to real estate prices is not immigration cut, but The Hormuz Straight remaining closed for at least another ≈2 months, as that would dry up a lot of the liquidity (higher prices, etc) from real estate and many other asset classes. Still, the only way out of this would be more monetary easing policies, because the whole modern economy is dependent on its refinancing capacity (so house prices go back up eventually).
If You Like Seatbelts, You'll Like ADDW
I came across this video where the author claims that starting from July 2026 all cars sold in the European Union are required to be equipped with Advanced Driver Distraction Warning (ADDW) system. This first part is true. Then, the author proceeds to conclude that the EU is mandating the installation of cameras and other sensors in the vehicles that would ensure that the driver is keeping both hands on the steering wheel and “not looking at the other stuff or phone” while driving. The author then takes a leap to connect this to electric vehicles and even central bank issued digital currencies! It's this second part that's problematic.
In short, the information shared in the video is highly misleading, and it doesn't look like the author is neither familiar with the legislation, nor with the technology underlying EVs. I'll go a couple of those points below.
First of all, there is no EU country whose laws provision for the driver to keep both of their hands on the steering wheel, or mandates the driver to keep their eyes on the road at all times. As such, the author+s claims and further conclusions taken on their basis lack substance.
Regarding the actual legal framework in the EU -- the law generally mandates for the driver to be as careful and attentful as possible at all times, which makes senes when you consider that an accident usually involves third-parties. There are many irresponsible drivers across Europe, and keeping a log in the vehicle of driving-related metadata is a very welcome addition. Such systems could be immensely useful in enforcing the law and the related court & insurance disputes, as well as incentivizing drivers to abide by the traffic law, thus safeguarding others.
Second, the government isn't pushing electric cars because "they're all connected to the internet". Most new cars are connected to the internet, it doesn't matter if it's gas, electric or horse-pulled. I'm not sure how this logic was further extended to mandated "digital wallets”, which are a Central Banking concept.
Third, public roads aren't for your entertainment, they quite literally have “public” in their name. The safety of others on the road cannot come at the cost of your personal driving habits or desires. If you go on a public road — you follow the law. There are plenty of designed places like race tracks and other private roads where you can lax the safety requirements at your own risk, without endangering others.

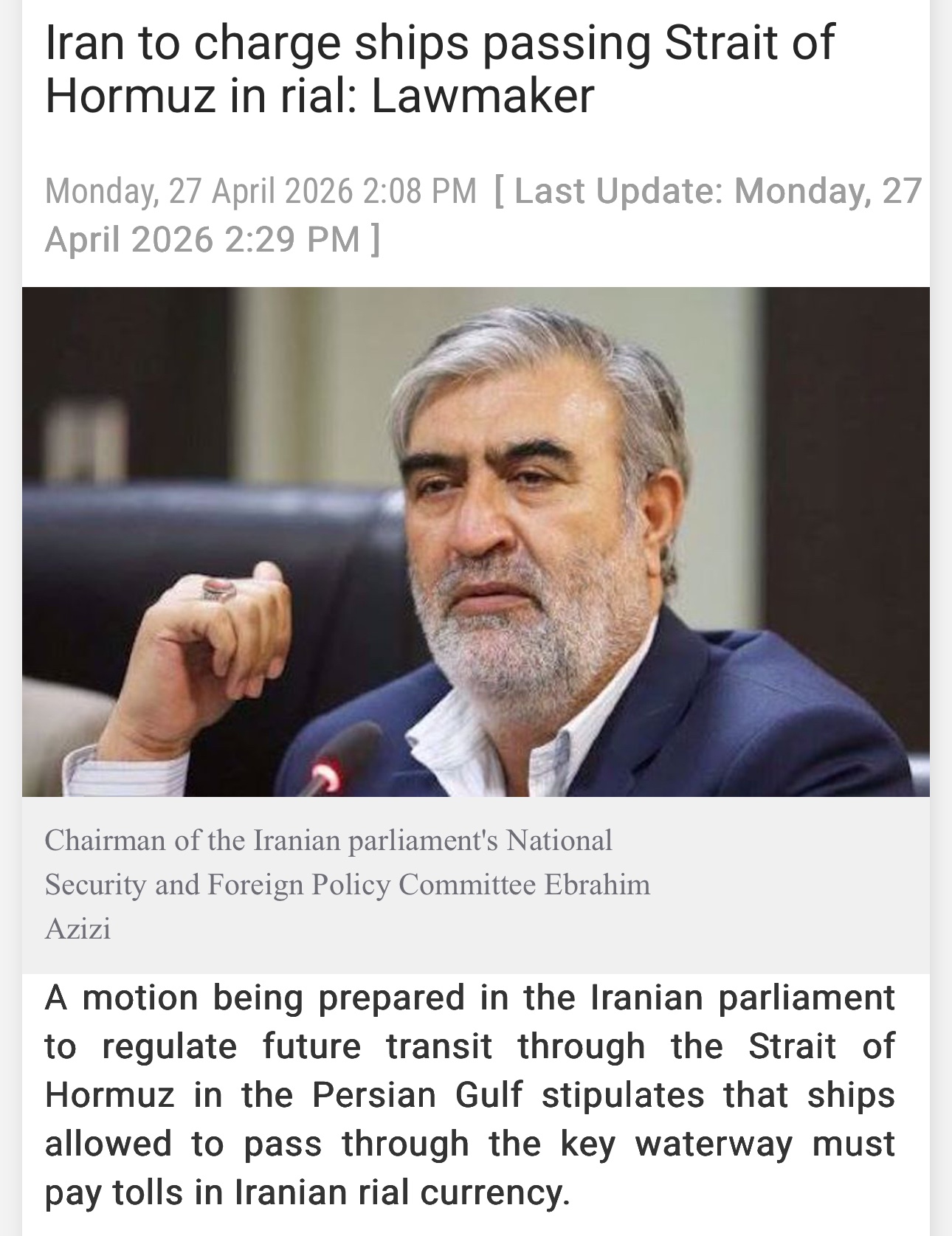
Iran To Require Rial For Hormuz Toll Payments
Unsurprisingly, it's been confirmed that Iran will not accept payments for its tolls in Bitcoin.
As I have explained a few weeks ago -- it would be counterproductive for Iran to do so. Now, it looks like Iran will require payments in their national currency - the Iranian Rial.
Unlike using Bitcoin, using Rial for settlements brings numerous advantages to Iran, which include flexible settlement (due to local central bank control); increasing demand for Rial whose value has recently collapsed due to sanctions/legal prohibitions aimed at Iran; and creating an incentive for re-integrating Iran into the global economy, thus effectively nulling at least a subset of sanctions
Bitcoin once again fails its test as an international reserve currency, but this isn't a surprise if read my numerous articles on this topic.
Iran Won't Accept Bitcoin For Hormuz Tolls
There is currently a wave of misinformation suggesting that Iran has chosen Bitcoin as their settlement medium for Hormuz Straight passage toll payments.
That’s complete nonsense. Iran would not gamble their Hormuz revenue on Bitcoin, or any other non-pegged crypto asset for that matter. If Iran would accept payments in cryptocurrencies (I don’t see why they wouldn’t), they would almost certainly effectively settle in a stablecoin.
Instead of investing Hormuz tolls into Bitcoin, Iran will most likely use them to buy gold, foreign exchange currencies (especially Yuan!) and budget deficits (which includes financing reconstruction efforts). This presents a type of an investment aimed at increasing the attractiveness of Iran government debt as collateral (in the longer-term), as well as the liquidity, value and use of Iranian Rial.
Moreover, Bitcoin is much easier to be sanctioned by Iran’s adversaries that the alternatives I presented, namely gold and Yuan. Unlike what many people may lead you to believe — you can certainly “blacklist” individual satoshis/coins, given that the transactional ledger is public by design. You can’t blacklist a gold atom (Au) 😁
I’m certainly not the only person that understands this, so I find it highly unlikely for Iran to choose Bitcoin over the prior alternative.
Are US Financial Policies Mirroring The 1720 Mississippi Bubble?
I came across this post that claims that the current US financial policies mirror the 1720 French Mississipi Bubble and suggests that Issac Newton saved Britain from major negative effects on the economy when the South Sea Bubble bust. It takes some strong conclusions based on arguments that are historically inaccurate.
While I understand the points regarding the Fed's balance sheet and I agree that it may be an issue. Generally speaking, I also equally oppose sovereign debt monetization by the central bank. However, I disagree that US/USD is in the same position as France/Livre in the 18th century. This is a good opportunity to go over some financial history of United States, France, Britain and even Isaac Newton:
1️⃣ France didn't have an international reserve currency in 1721, at that time the Spanish Dollar (the original “dollar”!) dominated international trade. So you cannot compare the United States Dollar in 2026 to French Livre in 1721 -- international reserve currencies are much more resilient to shocks. You cannot ignore the international status of a currency when reasoning about its demise. In several occasions, leading trade/reserve currencies outlived the sovereigns that created them (see example of Roman Denarius -- but again, it was commodity money, not paper FIAT). USD can survive a lot more "garbage on the balance sheet" than Ruble, and that's in big part due to the demand for USD-denominated instruments. US Treasury Debt instruments are the most desired financial collateral in the world -- it will take more than Bessent to destroy that privilege.
2️⃣ Newton was a master at the Royal Mint and he worked on coins, not the British economy. He also happened to miscalculate the market ratio between gold and silver (Britain was on a bimetallic standard), which had negative consequences on the British economy -- since gold was overvalued and silver undervalued, Gresham's Law kicked in and silver left Britain, with little silver coins remaining in the country. Arbitrage isn't free, so Britain would've been better off without an arbitrage opportunity on its money.
3️⃣ The South Sea Bubble of 1720 absolutely caused significant negative effects in the British economy. In fact, Isaac Newton lost an equivalent to several millions of USD when that bubble burst. The Pound did better than Livre because it was commodity money (gold/silver), while Livre was FIAT/paper, and consequently British economy recovered faster than French. It wasn't because Britain "had Newton".
Physical/Spot/Dated Brent indeed surpassed $100 per barrel within 24 hours and it took just a few more hours for undated Brent futures contracts to reach that price too
Crude oil prices have now increased by more than 25% since the April 17th pullback lows
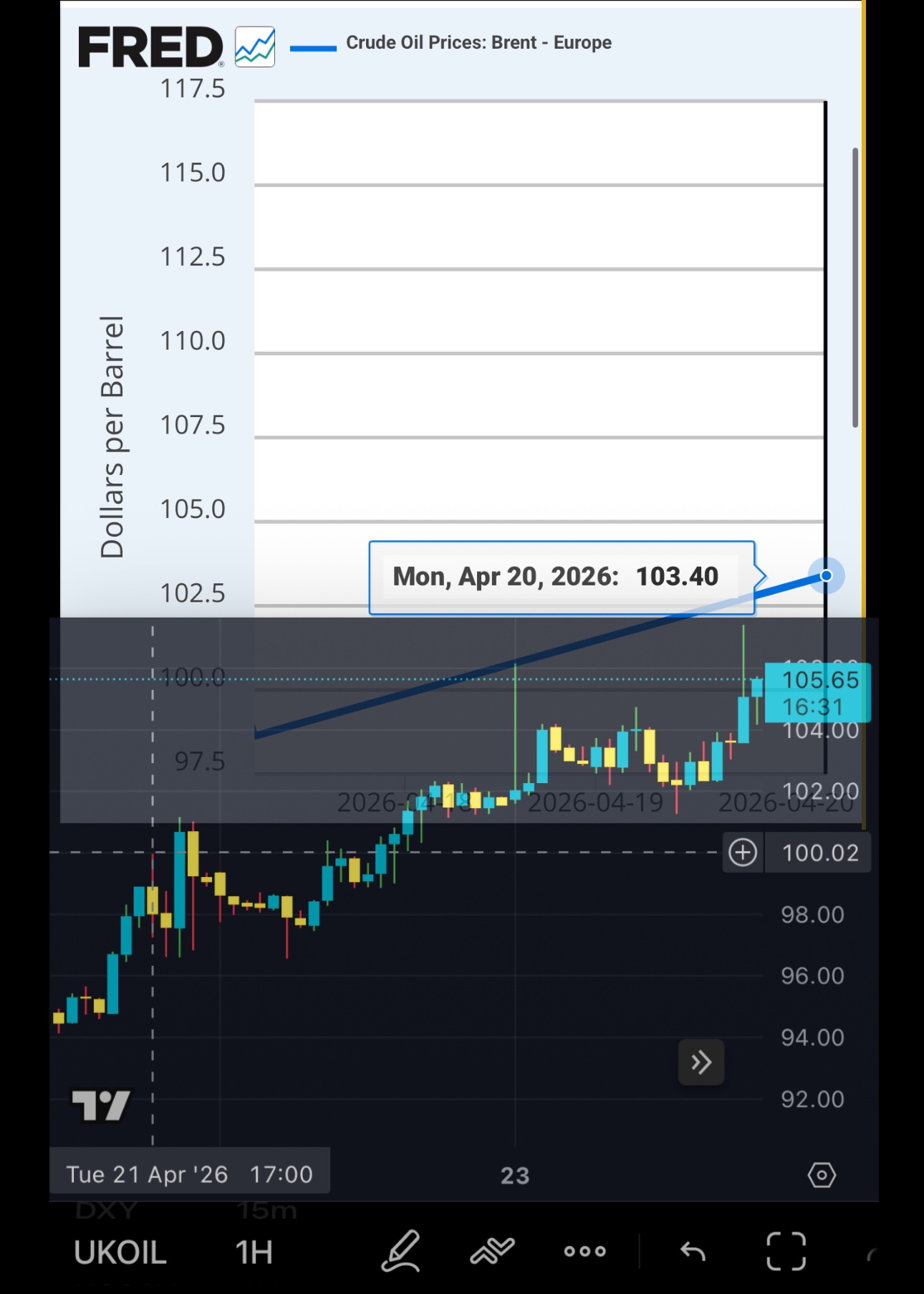
So I guess Brent will go above $100/barrel once again over the next 24 hours 😅
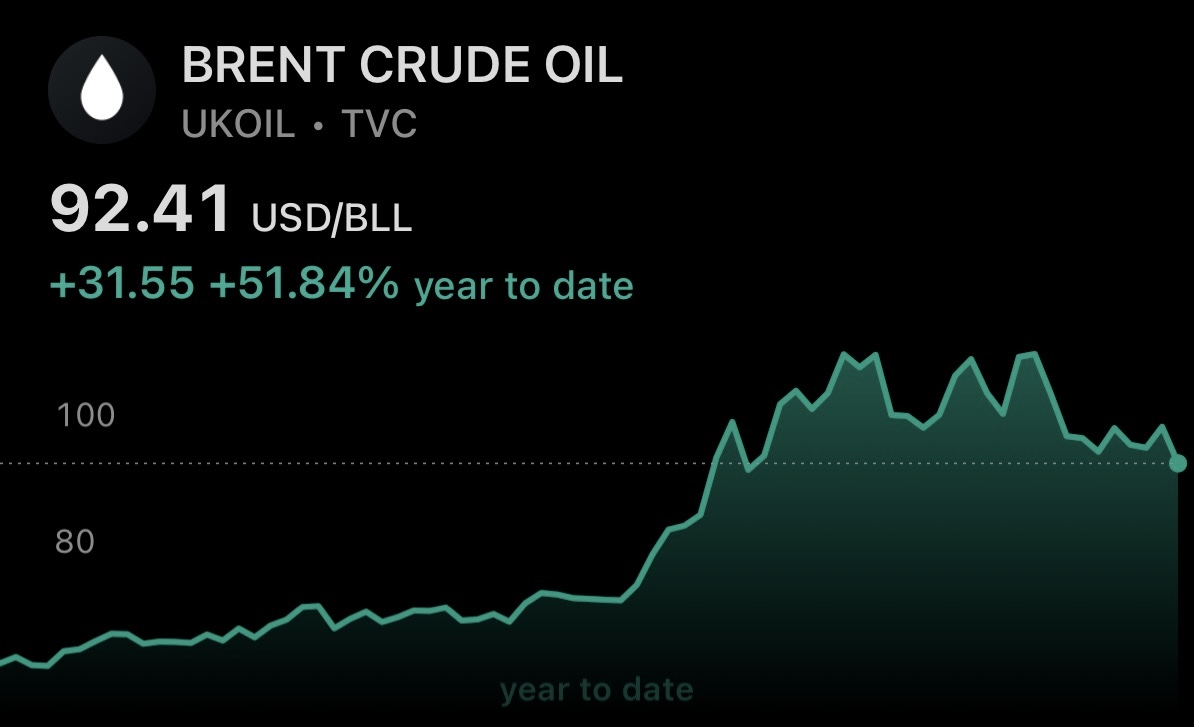
Iran war escalates once again, and the market moves consistently with the framework I outlined in a prior post:
(i) gold price down
(ii) crude oil price up
(iii) US Treasury debt yields up
As I've consistently pointed out, and in spite of contradicting claims by the U.S. Administration and mainstream media -- unfortunately, the Iran conflict is not yet over.
Keep watching the markets for developments -- they're much more accurate in their claims than third-parties.
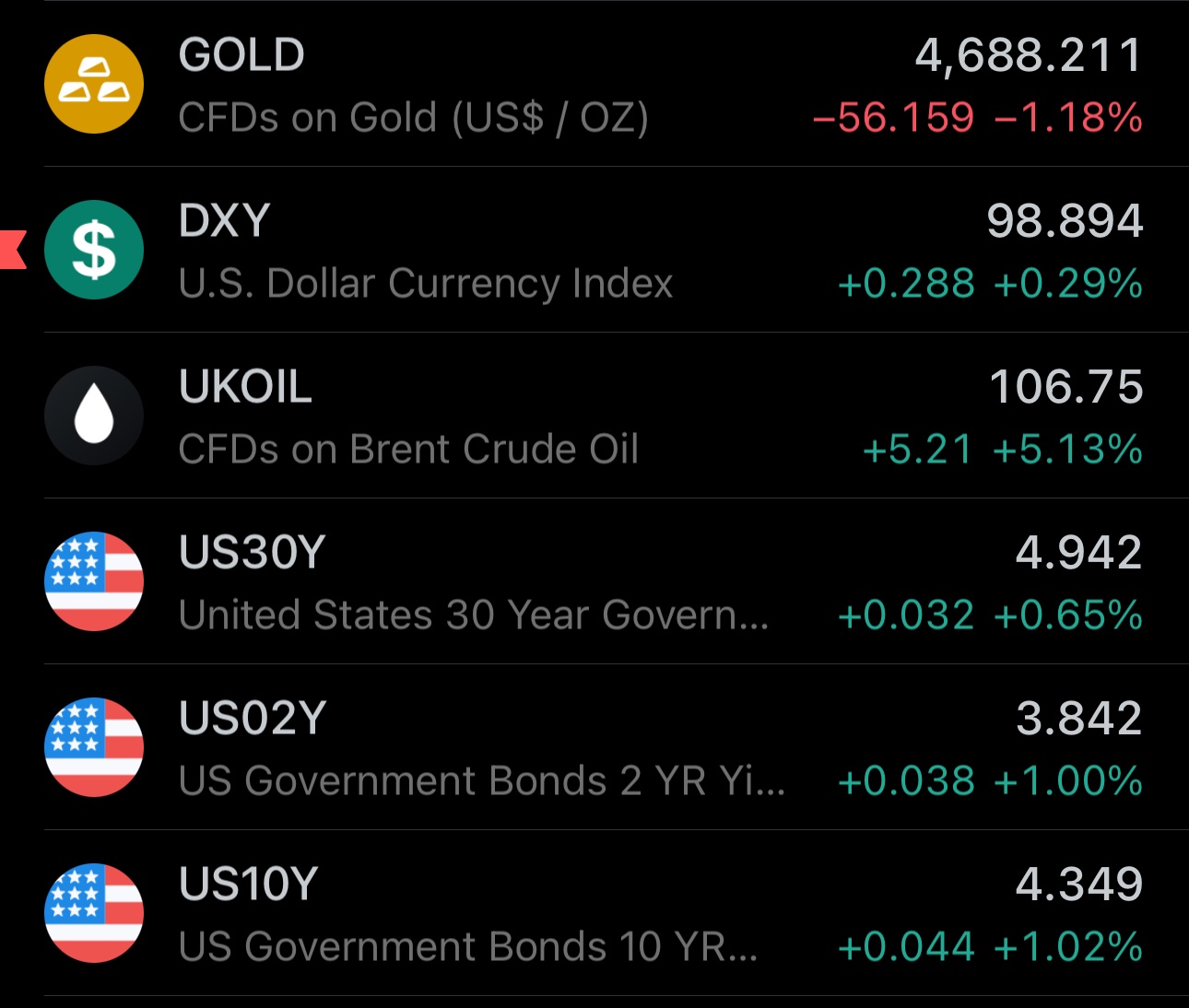
Straight of Hormuz reopens partially and markets signal de-escalation in exactly the same manner I explained in my earlier post:
(i) US Treasury debt yields & term premia go down
(ii) Crude oil price falls significantly
(iii) Gold price continues upward towards re-testing $5000
While these market moves do not constitute a confirmation of an end to the Iran war, nor erase the potential for renewed escalations, the market is coherently signaling a material de-escalation event. However, as I have noted last week -- prepare for a lot of volatility. We'll need to wait at least until the end of Monday for a longer-term confirmation.
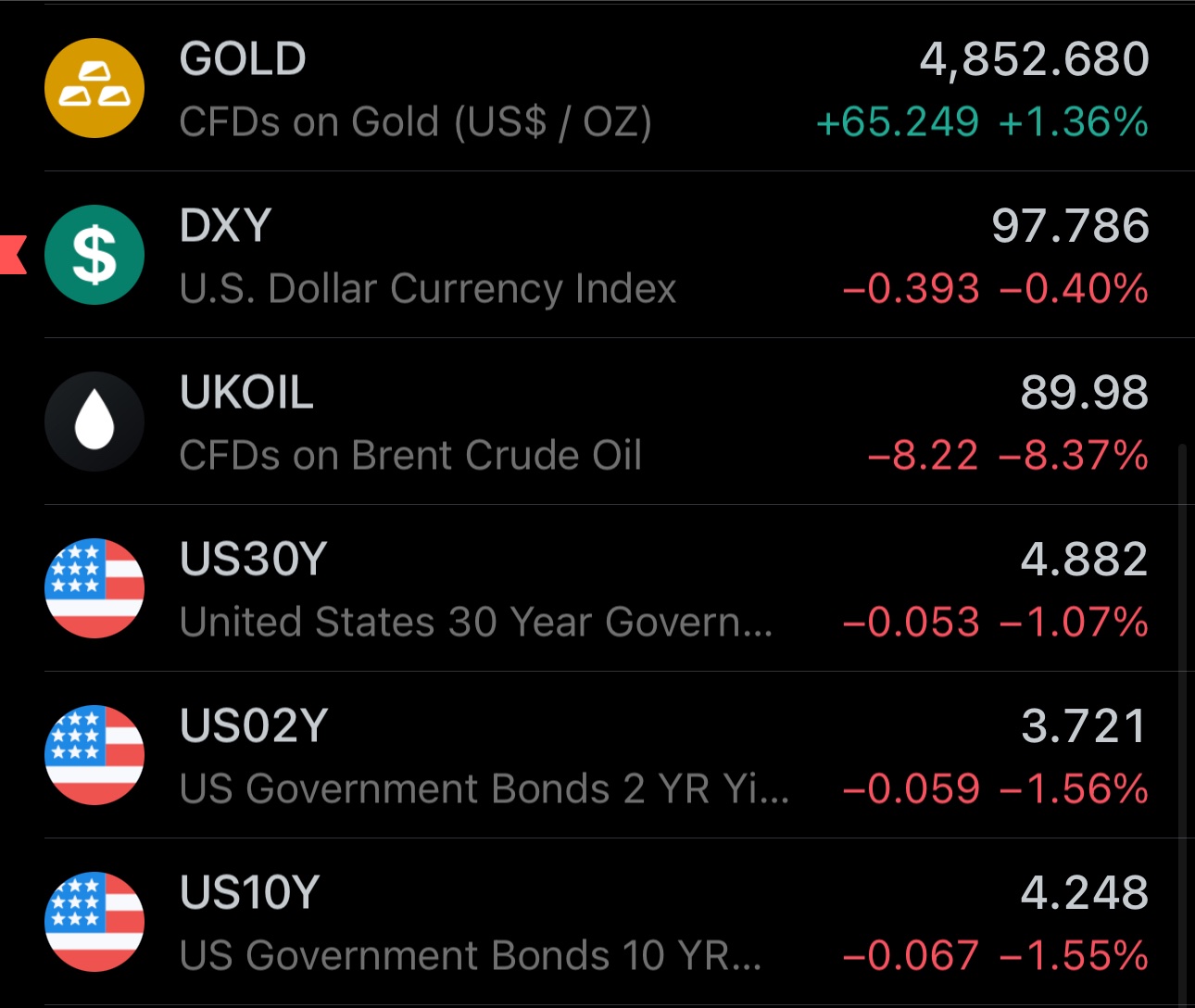
Although S&P 500 is unlikely to open green today, due to increased risks of energy supply shock, it wouldn't be "shocking" if it did
The U.S. stock index by itself will tell you little about the near-term direction of the economy and geopolitical developments

So I guess Brent will go above $100/barrel once again over the next 24 hours 😅
Iran Is The Legal Owner Of Frozen Assets
Contrary to what some are suggesting -- returning frozen assets to Iran would neither constitute a gift, nor a new payment.
Under U.S. sanctions law, freezing/blocking an asset does not automatically transfer its ownership or cancel the underlying payment obligations. The blocked entity foregoes the rights to use, transfer or withdraw, but not ownership.
U.S.-sanctioned assets are a mixture of deposits, gold, US Treasury debt instruments.
Under the law governing these sanctions Iran remains the legal owner of those assets, while requiring authorization to exercise the usual ownership powers.

Straight of Hormuz reopens partially and markets signal de-escalation in exactly the same manner I explained in my earlier post:
(i) US Treasury debt yields & term premia go down
(ii) Crude oil price falls significantly
(iii) Gold price continues upward towards re-testing $5000
While these market moves do not constitute a confirmation of an end to the Iran war, nor erase the potential for renewed escalations, the market is coherently signaling a material de-escalation event. However, as I have noted last week -- prepare for a lot of volatility. We'll need to wait at least until the end of Monday for a longer-term confirmation.
Bond Markets Signal An Escalation In Iran War
While the majority of mainstream financial analysis seems to be pushing the idea of Iranian conflict coming to an end, using the new all-time highs in S&P 500 as a pretext, the U.S. bond market is communicating a different story.
Not only the yields on US Treasury issued debt securities continue to increase across all tenors, but so is the term premia on that government debt. This means that creditors to the U.S. government are not only requiring higher interest payments, but also a higher premium for longer-tenor instruments. Such moves in the bond market could be indicative of:
(i) increased future financing;
(ii) weakening U.S. dollar;
(iii) reduced demand for U.S. Treasury debt instruments / USD assets;
This is coherent with what would happen under the scenario where U.S. increases their involvement in the Iran war, thus escalating from the current point. Historically, expanding military commitments are almost unanimously associated with increased government/state/empire spending. 15th century Naples financed military campaigns of sovereigns at interest rates that at times reached ≈40%, expressing the high risk of such ventures.
Of course, I'm not suggesting that the mere increase in government debt yields and term premia is an indication of further military escalations between U.S. and Iran, but rather that their increase under the current regime is. Other corroborating factors include:
(i) crude oil still trading above $90/barrel;
(ii) USD weakening against other FX currencies, in spite of raising oil prices;
(iii) gold'd price not increasing significantly, as it likely would, had the war-induced energy crisis would indeed be headed towards a resolution;
These developments are happening while both Iran & U.S. are exercising a military control over the Straight of Hormuz, yielding it to become closed in part. In case this were a sure de-escalation stage, I would expect the bond yields and term premia to be relatively more suppressed, oil price trending down more decisively, and gold closer to/re-testing the $5000/oz price.
Regarding the new all time highs of S&P 500, upward price movements of the U.S. stock market index alone cannot be used as a strong signal against systemic crisis or large market downturns. History is very clear on this, and you don't need to look very far: S&P rallied in 2007, before taking a massive downturn during the 2007-2009 Global Financial Crisis in the U.S. Post-2008 financial regime is significantly more dependent on refinancing capacity, which amplifies volatility.
I am hoping for a fast and lasting peace, as millions are suffering both directly and indirectly. However, taking everything into consideration, in my view, the markets are neither signaling a significant and lasting near-term geopolitical de-escalation in the Iran war, nor an imminent resolution to the energy supply shock it induced.
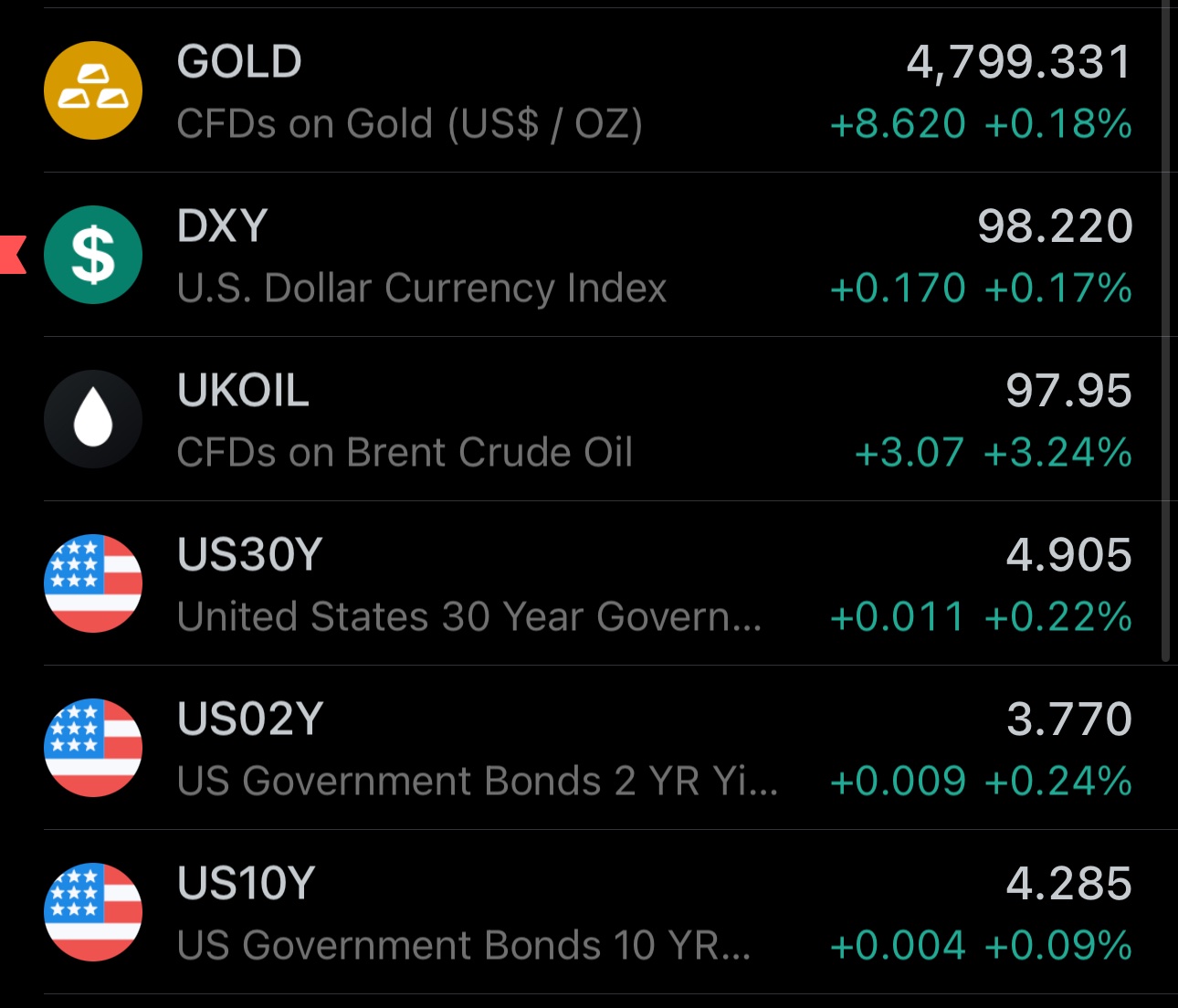
Bond Markets Signal An Escalation In Iran War
While the majority of mainstream financial analysis seems to be pushing the idea of Iranian conflict coming to an end, using the new all-time highs in S&P 500 as a pretext, the U.S. bond market is communicating a different story.
Not only the yields on US Treasury issued debt securities continue to increase across all tenors, but so is the term premia on that government debt. This means that creditors to the U.S. government are not only requiring higher interest payments, but also a higher premium for longer-tenor instruments. Such moves in the bond market could be indicative of:
(i) increased future financing;
(ii) weakening U.S. dollar;
(iii) reduced demand for U.S. Treasury debt instruments / USD assets;
This is coherent with what would happen under the scenario where U.S. increases their involvement in the Iran war, thus escalating from the current point. Historically, expanding military commitments are almost unanimously associated with increased government/state/empire spending. 15th century Naples financed military campaigns of sovereigns at interest rates that at times reached ≈40%, expressing the high risk of such ventures.
Of course, I'm not suggesting that the mere increase in government debt yields and term premia is an indication of further military escalations between U.S. and Iran, but rather that their increase under the current regime is. Other corroborating factors include:
(i) crude oil still trading above $90/barrel;
(ii) USD weakening against other FX currencies, in spite of raising oil prices;
(iii) gold'd price not increasing significantly, as it likely would, had the war-induced energy crisis would indeed be headed towards a resolution;
These developments are happening while both Iran & U.S. are exercising a military control over the Straight of Hormuz, yielding it to become closed in part. In case this were a sure de-escalation stage, I would expect the bond yields and term premia to be relatively more suppressed, oil price trending down more decisively, and gold closer to/re-testing the $5000/oz price.
Regarding the new all time highs of S&P 500, upward price movements of the U.S. stock market index alone cannot be used as a strong signal against systemic crisis or large market downturns. History is very clear on this, and you don't need to look very far: S&P rallied in 2007, before taking a massive downturn during the 2007-2009 Global Financial Crisis in the U.S. Post-2008 financial regime is significantly more dependent on refinancing capacity, which amplifies volatility.
I am hoping for a fast and lasting peace, as millions are suffering both directly and indirectly. However, taking everything into consideration, in my view, the markets are neither signaling a significant and lasting near-term geopolitical de-escalation in the Iran war, nor an imminent resolution to the energy supply shock it induced.
Bitcoin Can't Become A Reserve Asset Without Protocol Changes
If you believe in a future where Bitcoin challenges existing international reserve currencies, it makes no sense to oppose changes to its core design. Bitcoin is here to serve a purpose, and given this, the protocol MUST evolve in response to the changes in the environment. History agrees.
First, if you commit to freezing an architectural implementation of the protocol you are erasing one of the core benefits of cryptocurrencies, which is the fact that they are programmable. The fact that Bitcoin is a computer program at its essence, you can change with little cost. This programmability is one of the most attractive points of algorithm-based currencies, as you can adapt to change/new environments at a smaller cost. It makes no sense to forego this benefit. The protocol MUST evolve.
Second, historically, every major international reserve currency was backed by an issuer with a strong legal and control system over all monetary aspects. An issuer whose currency/money provided for enough liquidity and resisted debasement over an extended period of time was seen as attractive to store and settle trades in. Given that geopolitical, social and economic regimes change over time, a successful reserve currency is one that is able to adapt to those changes, while still accommodating for its liquidity and store of value goals. As such, evolution/change of the Bitcoin protocol is strictly necessary for Bitcoin to even have a shot at becoming a significant portion of international settlement, as Bitcoin needs to accommodate for the technology risk in the same manner that government-like issuers historically did via their legal, tax and monetary policy systems.
Given that quantum risk jeopardizes the intended integrity of the existing ledger, it's crucial for the Bitcoin protocol to mitigate that risk an not "just let it happen". This is what a highly trusted issuer would have done.
Why Physical Oil Trades Above Paper Oil
I doubt that "energy analyst experts" can't explain why physical crude oil is trading above CDFs, but I will:
Physical trades above paper, because there is a physical supply shock. Economic downturn expectations put negative pressures on oil futures. This is similar in principle to what happened with gold & silver a few weeks ago. Basis drift is a common occurrence. This drift is bigger during shocks, like what is occurring now.
Iran Ceasefire Has Already Been Broken
Yesterday I made the following predictions, throughout several posts:
1️⃣ There would be no escalation/no attack on April 7th 8PM ET deadline. Today, this showed to be correct.
2️⃣ Oil prices are not coming back to their start of year prices and will exhibit elevated volatility. This has been the case throughout today.
3️⃣ The military conflict in Iran is not over, and the ceasefire is unlikely to last for a long time. Unfortunately, this last point has also materialized.
Beware of the abundant noise in mass information media, including through a deliberate strategy of using of official government communication as a form of information warfare. There's also numerous instances of anecdotal/fake news being presented as facts by major news outlets (I covered some of them earlier today).
Keep paying close attention to government debt yields, precious metals and oil. In my prior posts I explained the exact patterns to look for in their joint movements.

Iran Won't Accept Bitcoin For Hormuz Tolls
There is currently a wave of misinformation suggesting that Iran has chosen Bitcoin as their settlement medium for Hormuz Straight passage toll payments.
That’s complete nonsense. Iran would not gamble their Hormuz revenue on Bitcoin, or any other non-pegged crypto asset for that matter. If Iran would accept payments in cryptocurrencies (I don’t see why they wouldn’t), they would almost certainly effectively settle in a stablecoin.
Instead of investing Hormuz tolls into Bitcoin, Iran will most likely use them to buy gold, foreign exchange currencies (especially Yuan!) and budget deficits (which includes financing reconstruction efforts). This presents a type of an investment aimed at increasing the attractiveness of Iran government debt as collateral (in the longer-term), as well as the liquidity, value and use of Iranian Rial.
Moreover, Bitcoin is much easier to be sanctioned by Iran’s adversaries that the alternatives I presented, namely gold and Yuan. Unlike what many people may lead you to believe — you can certainly “blacklist” individual satoshis/coins, given that the transactional ledger is public by design. You can’t blacklist a gold atom (Au) 😁
I’m certainly not the only person that understands this, so I find it highly unlikely for Iran to choose Bitcoin over the prior alternative.
As I correctly explained, there would be no attacks on Iran today, contrary to what was heavily suggested by the U.S. administration
I would like to be clear that I don't believe this is the end of the conflict.
It's also a question of how long the ceasefire will last for, given the historical tendency of its violation by the offensive parties.
Additionally, don't expect oil prices to return to the levels seen at the start of the year anytime soon. Prepare for volatility on that side. It's also becoming evidently clear that the legal regime of Straight of Hormuz won't return to its pre-war state, which further supports the longer-term upward price pressure on the commodities that transit through it, including crude oil, natural gas and fertilizers.

Unsurprisingly, the deadline for Iran attack had been extended
I explained why a few hours before the ceasefire was officially announced. The market was very clear on this one.
While as whole the market may appear noisy, if you correctly isolate the right signals you can frequently derive a useful model for the future.
For this case, you could focus on the following 3 asset class prices under the current regime: gold, US Treasury debt yield and oil prices. If the escalation were to happen today we wouldn't see gold up, oil down and bond yields down like we did prior to the trading day close. Instead, if an escalation were indeed to occur in the next hours, you'd see something like gold down, oil up and bond yields up (short-term, the yields may be pushed down due to collateral demand, but increased future costs would soon push the term premia higher).
This was one of the times where the market signal was extremely congruent with an upcoming reduction of military escalations.

The Iran attack deadline will be extended
To me, the market is clear on this one
You wouldn't see oil down, gold up and government debt yields down. In case an attack would occur in the next few hours, gold would be down, oil up, yields likely up as well
Next few hours will confirm this
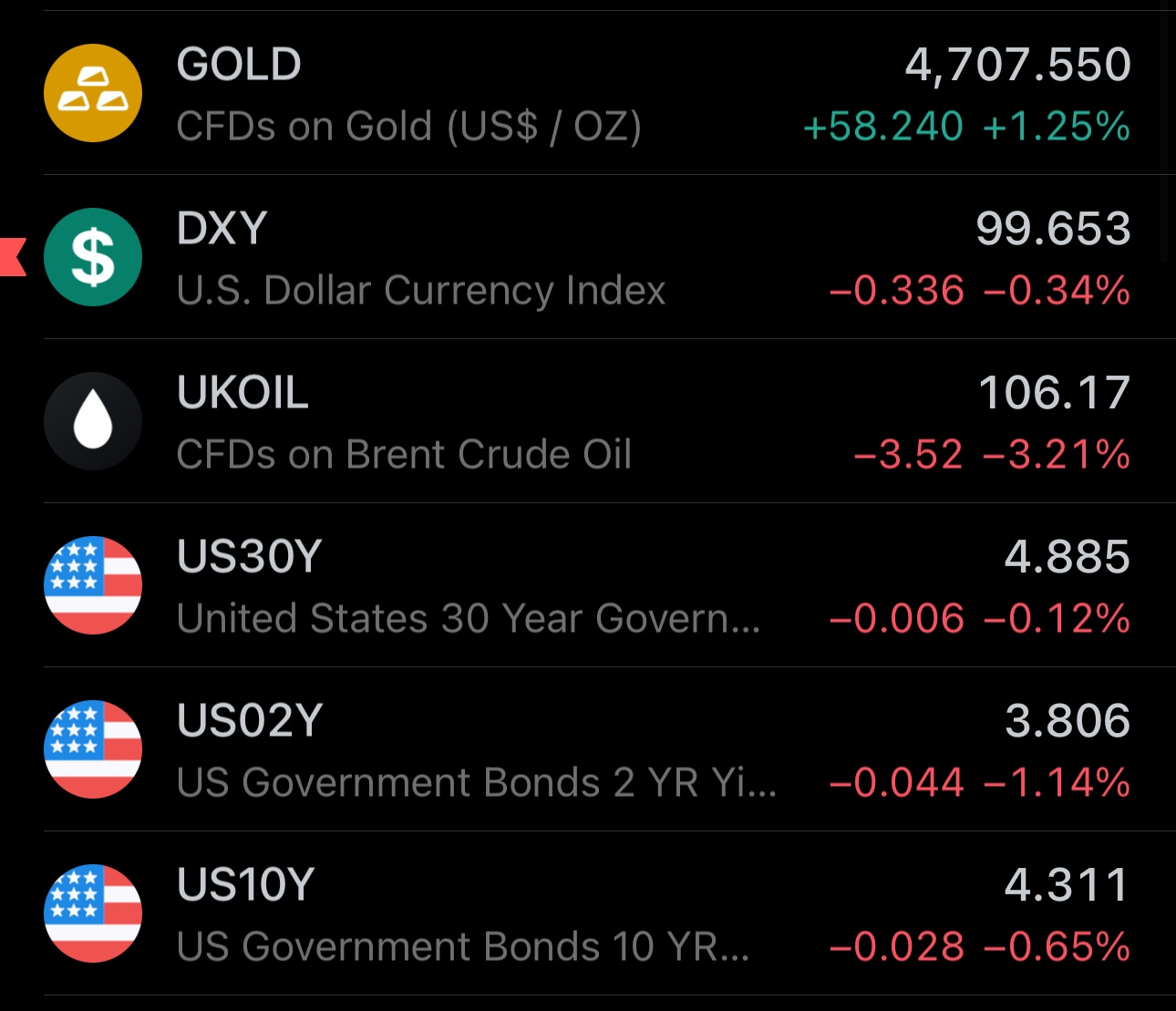
The Iran attack deadline will be extended
To me, the market is clear on this one
You wouldn't see oil down, gold up and government debt yields down. In case an attack would occur in the next few hours, gold would be down, oil up, yields likely up as well
Next few hours will confirm this
No, gold is not in a bear market
Do you really believe that identifying a bear market in an asset class is as simple as ascertaining an X% decrease in a Y period of time?
When I get some time, I'll write an article explaining what drives the price of gold, and why this is NOT the start of a bear market or the macro cycle top for precious metals
The best part about carefully instructing an agent to implement payment integration overnight is coming back to a 6000 line Python file containing a class with 161 methods 🫠

Don't Expect $60 Oil In 2026
$36 billion worth of oil will be released from strategic reserves of 32 countries, in an effort suppress the oil's price down price down. However, I don't believe those efforts will be enough.
International Energy Agency (IEA) has just approved the largest oil release from its member countries strategic reserves. As an emergency measure, 400 million barrels of oil will be channelled into the markets from sovereign reserves, which is more than double of the previous record of 182 million barrels in 2022. Replacing Russian oil in 2022 was mostly a supplier problem, while Straight of Hormuz is a major route for many suppliers, making the disruption of flow through it a global logistics challenge. I consider this to be objective stress signal on the oil supply market, which acts as upwards price pressure. The market seems to agree with me, at least in the short term, given that even on these news Brent Oil is still trading around ≈$90 per barrel.
While the release of oil reserves by IEA members will exert downward pressure on the price of oil while that release lasts - there is no free lunch. Not only those reserves would need to be replenished, but it also expose the IEA countries to increased risk due to reduced domestic oil supply. This is another supply stress factor that will need to be resolved.
Geopolitical risk is perhaps the most obvious driver behind the recent oil price increase, and even in case of a de-escalation the risk will decrease to levels that are higher than at the start of 2026. The damaged oil production and logistics infrastructure will also need to be restored and other similar costs covered. As such, the geopolitical risk baseline has been elevated, and it will remain elevated at least until the end of this year.
For these reasons, it will probably take a while for the oil prices to decrease towards the ≈$60 area. To be very specific - I don't believe oil will fall down to $60 in 2026.
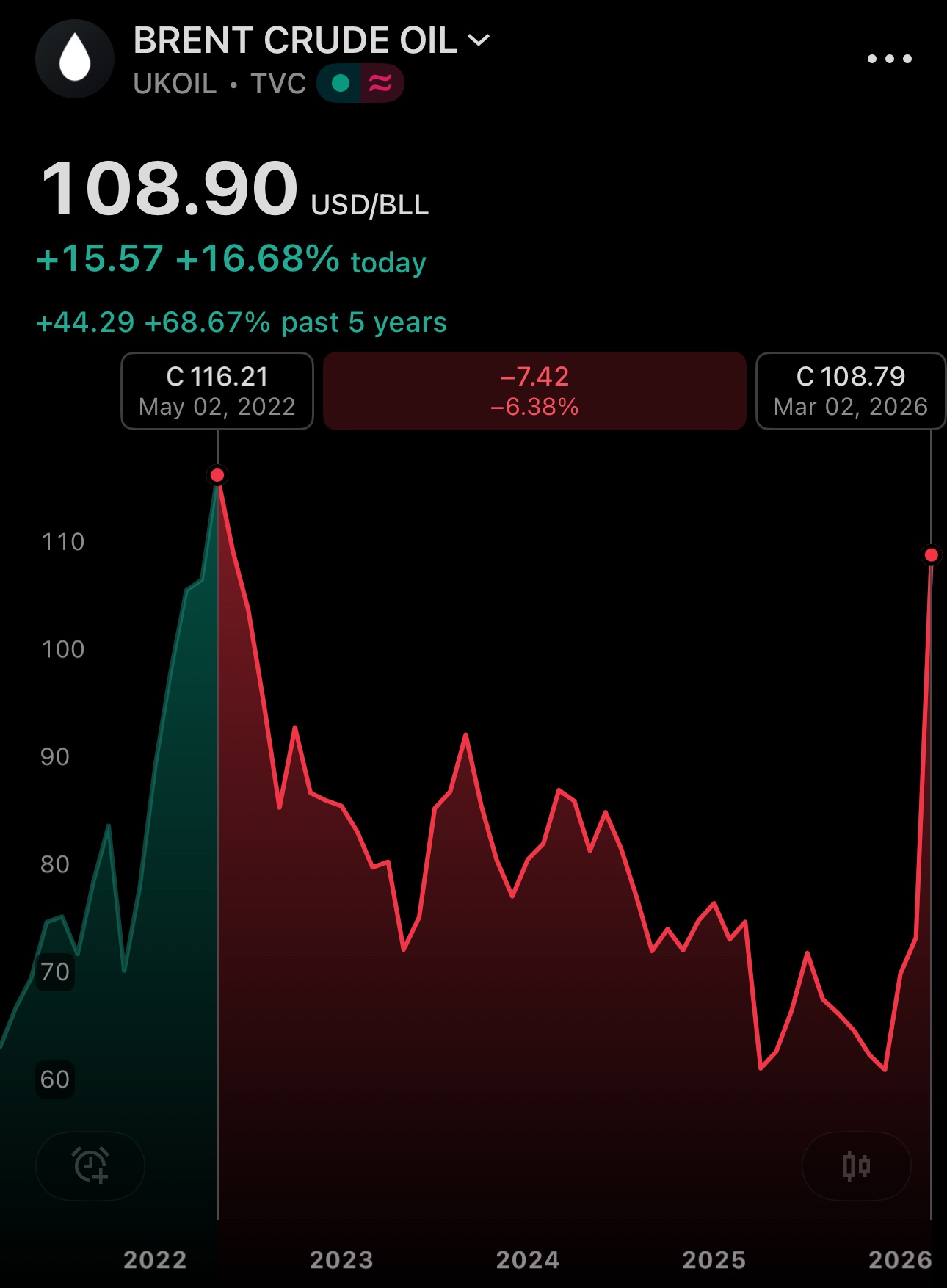
And just like that... highest oil prices since 2022 -- just a few percent shy from the heights of May 2nd 2022
I have first warned about an incoming large increase in oil prices ≈8 months ago
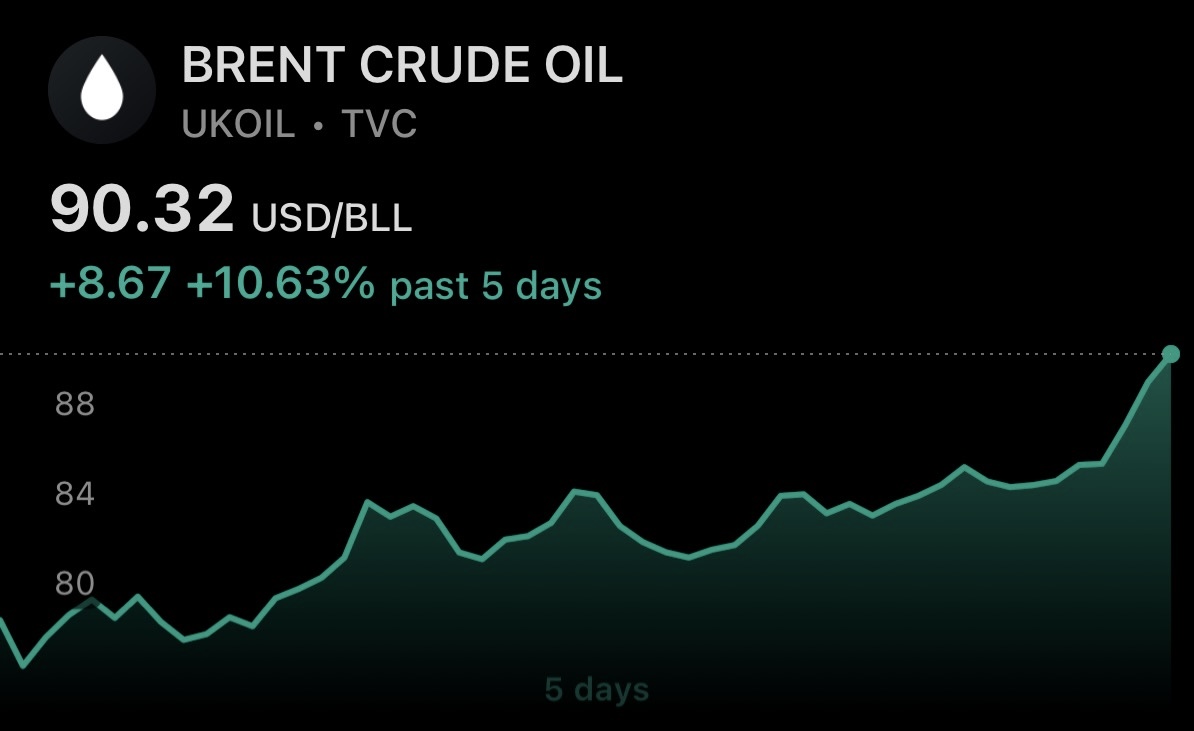
Brent Crude Oil breaks above $90, and its headed higher!
You can add this to my list of correct predictions. Last time oil was this expensive was more than 2 years ago in 2023.
Perhaps it's obvious at this point -- but it won't top out at $90 😄
Going long on Bitcoin now at $68K is very risky (and maybe brave!). I would't do it
There is too much negative pressure on global liquidity, which makes downward price shocks in the near term much more likely
And once again -- global liquidity is not measured by M2, that's only a part of it.
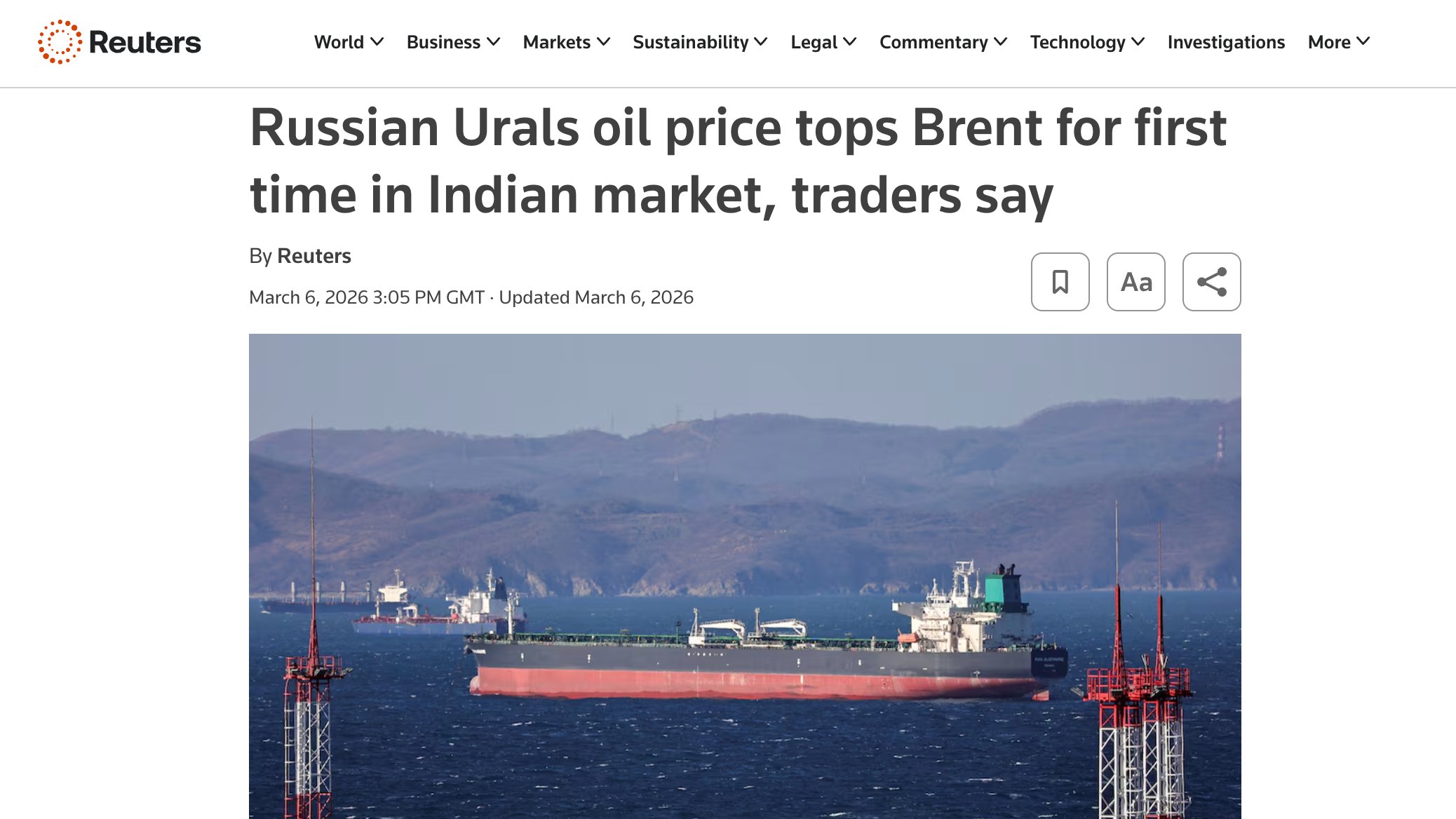
Crue Oil: United States Acts, Russia Benefits (Once Again)
Despite the heavy international sanctions, Russia is now selling Urals oil at a ≈$5 premium over Brent oil. Usually, Urals trades at a discount to Brent, so this is a relatively unusual situation. This is, of course, caused by the U.S. military force use against a sovereign nation once again.
While oil production and export from the Arab Gulf region has now greatly reduced, the demand for oil didn't follow that downtrend. 20% of all oil passes Straight of Hormuz, the flow through which is now heavily limited. As a result, a significant part of that demand has now shifted towards Russia, which is capitalizing on that demand by selling crude oil, not only for a higher price, but also at a premium!
High oil prices are also great news for Ruble. More than ≈50% of Russian oil exports are in foreign currencies, but exporters must pay their taxes in Rubles. As such, exporters must sell foreign currencies to purchase Ruble, which drives its price up. Additionally, since 2020 Russia has policies in place which cause high oil prices to usually lead to further accumulation of gold by the Central Bank of Russia (CBR): excess revenue from taxes resulting from oil sales above ≈59$/barrel are directed to the NWF for investing in precious metals (mostly gold) and FX (mostly renminbi/yuan). So instead of spending the extra revenue immediately, it gets invested.
The mechanism by which the FX & gold purchase happens from excess gas and oil revenues is also interesting to explore. NWF is administrated by Russia’s Ministry of Finance (MoF), and it’s effectively MoF doing those purchases on behalf of NWF. So every time revenues from oil and gas taxes exceed the benchmark price, the MoF buys foreign assets and gold from the CBR, which then immediately repurchases what it had just sold to the MoF/NWF. As a result of this sanitization mechanism, the Central Bank of Russia net holdings of gold/FX currencies remain constant, while the net asset holdings of the NWF increase — so in net terms the Russian government holds more gold and FX.
Imagine on a given period Russia recovered an extra revenue of $100M over the benchmark. Under the structure described above, the Russian government will not immediately spend those $100M, but instead invest them into gold & FX currencies. The step-by-step process looks something like this:
1. MoF buys $40M worth of gold from the CBR
2. CBR repurchases $40M worth of gold from domestic Russian market, using the proceeds from 1
3. MoF buys $60M worth of renminbi from the CBR
4. CBR repurchases $60M worth of renminbi from FX markets, using the proceeds from 2
As you can see, the combination of steps above leaves Russia with more gold and FX reserves than before.
For the month of March 2026, the Russian Federation has paused the gold/FX purchases from excess revenue from oil and gas. However, I don’t think that this pause will remain in effect much longer, as it has been explicitly linked to lowering the Ural’s oil revenue threshold from the current ≈$59 per barrel, potentially down to $45-50 per barrel. For now, all of the excess revenue from oil and gas will be going to the federal budget, available for its immediate liquidity needs.
So whichever way you look at it — Russia massively benefits from the raise in price of commodities and precious metals, namely gas, oil, gold and silver.
Reordering of a 5 billion row DuckDB table completed yesterday 🎉
The whole process took less than 48 hours. Excited to integrate DuckDB as the main data abstraction layer for the neural network-based models that will be trained on the LOB data. If everything goes well -- it will become the new default.
