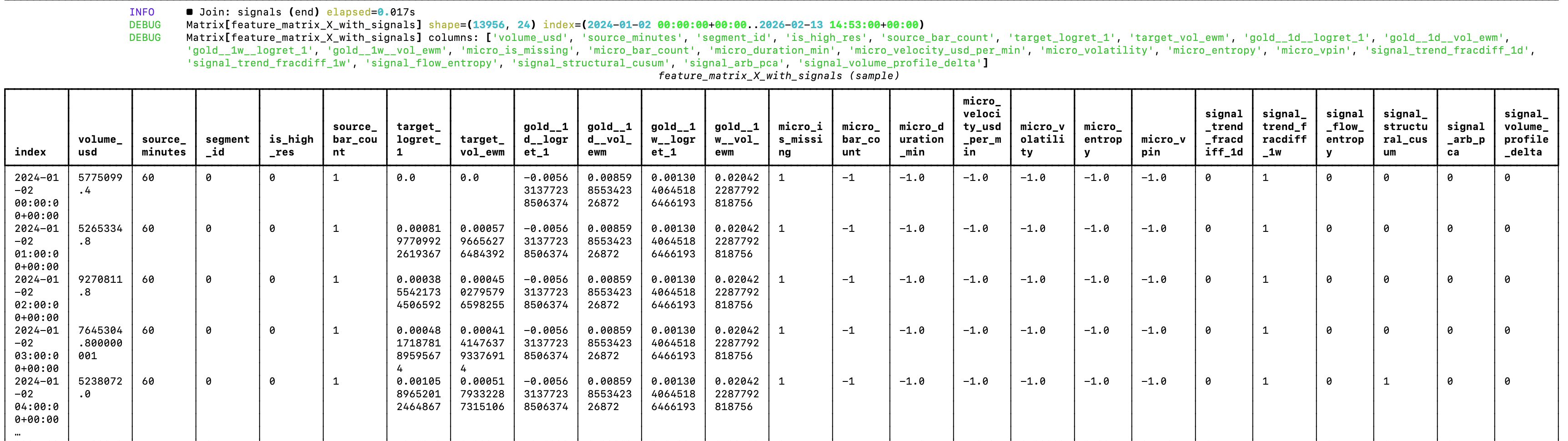
The random forest that guides my model factory needs refactoring
While the current architecture shows good prospects for generating profitable trading models, the random forest is currently a bit of a mess 😅 If you look at the image attached to the post, you can see why.
Since the random forest can’t extrapolate, features like the date and source segment will just make the forest learn on noise (it will train on association between those features, e.g. it’s not very useful to learn that volume in 2025 was higher than in 2024). But this was expected. The goal was to validate an architectural approach that could work. Now it’s time for optimizations and changes. Actually, changes before optimizations.
Another thing that I’ll get rid of is the hybrid spine for supporting data from multiple timeframes, as the model didn’t extract any meaningful alpha — and some of it has even confused the random forest. I’m sure there is way to make even with limited data, but I’ll be moving to testing it on dataset for which I have access to highly granular data (hello, Bitcoin!). So the logic of the data loader in the pipeline will be greatly simplified.
I’ll also make the labeler configurable, so that you can use the same set of features for different types of predictions. For example, you could have the “unconstrained” standard deviation labelling in the sense hat you can enter and exit the position at any time, to constrained logic scenarios such as the ones of Polymarket’s 5-minute price predictions on Bitcoin, where you can only enter a position at specific times, and the resolution happens at specific times (e.g. at the end of every 5th minute of the day, starting from 0).
The core logic of the ML pipeline remans the same.