
Out of Sample Permutation Feature Importance For Random Forest’s Feature Optimization
After the first level of tuning of the random forest’s parameters, it came time to optimize the features on which the random forest gets trained on. I’ve already did a minor cleanup, but I didn’t yet test for the predictive importance of each feature in the random forest.
To optimize the random forest’s features, I’m using Out of Sample Permutation Feature Importance (OOS). The OOS approach consists in three core steps:
1️⃣ Train the random forest once on the training data
2️⃣ Take out-of-sample validation data (testing data), permute the values of a single feature/values within the same column and pass them to the model trained in step 1.
3️⃣ A feature is important for the model if the model’s predictive power reduces significantly when that feature’s values are randomly shuffled.
The “out of sample” part refers to the fact that the set of data used to train the model and evaluate it after permutations is distinct, thus reducing the contribution of noise to the evaluation metrics. By default, scikit-learn uses Gini Importance to rank features by their utility to the model. Gini is a bad metric for my data because of:
➖ High cardinality bias (it has an inherent bias towards continuous variables, and some of my features are discrete)
➖ Gini importance is computed on the training data
➖ In case of two correlated features, the random forest will randomly pick one at each split, but Gini will actually divide the importance between the two
Additionally, the out-of-sample Area Under the ROC Curve (AUC) of 0.7566 is unrealistically good for predicting 5-minute Bitcoin price moves. This value implies that if you pick a random 5-minute winning window and a 5-minute losing one, my model ranks the winner window ≈76% of the time. Either I found a model that beats virtually every financial institution in existence, or there is a lookahead bias and overfitting happening in the model.
Conclusion: my meta forest — the “seconds_to_settle” feature is basically carrying the entire model 😂 So in its current state, the random forest is training almost entirely on the time of day/time to expiration. The cleanup has started.
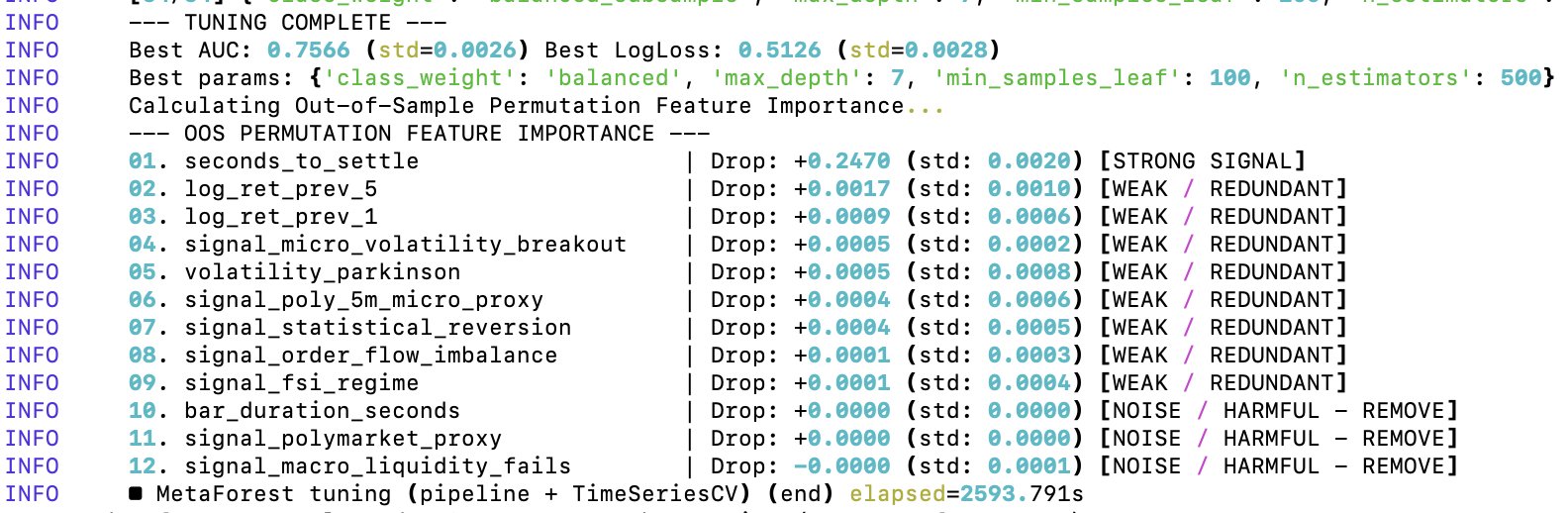
As a result of the first step in optimizing/prioritizing the random forest’s features -- I've dropped about half of them 😁
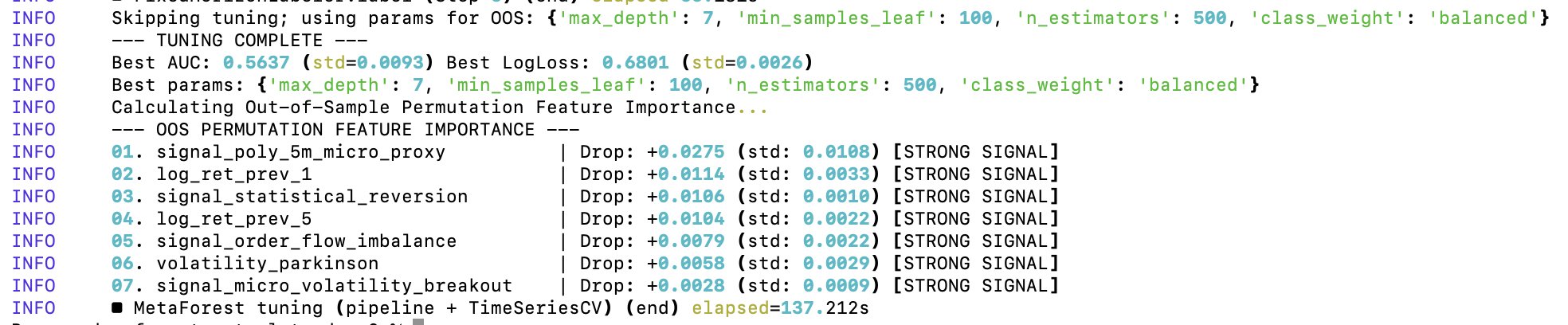
The random forest's features have been heavily refactored. I also replaced the polymarket feature with lookahead bias (the proxy model) with a combination of other indicators.

The model factory has been refactored to use a DSL for configuring the pipeline -- so now you can visualize and configure the whole flow from a single place
This also makes it easier for agents to autonomously discover and verify profitable trading strategies, but I'll cover that in more detail in another post 😁
