Machine Learning
Ongoing notes on machine learning and AI systems, including forecasting models, evaluation techniques, and practical workflows for financial and technical analysis.

Using DuckDB To Train A Neural Network On 500GB Of Price Data
I have ≈500GB of historical Bitcoin level 1 limit order book data to process and train a neural network on.
I don't want to overcomplicate the data access layer and definitely want to keep all of the training, validation and inference in Python. A simple file-based DuckDB setup sounds like a good solution for this, as it allows for iterative in-memory data loading within the model training code -- this is because DuckDB already implements all of those nice abstractions that allow it to load large datasets lazily/on-demand. So I'll neither need 500GB of RAM, nor a dedicated DBMS process.
The model will be trained using a walk-forward strategy, so several versions of neural network weights/trained models will be generated. This means the amount of data loaded into the memory will be limited in either case. I may rely on DuckDB for some algebraic processing when querying data, but for now I'm planning to mostly filter for events within a specific time range.
I used DuckDB several times before for finance applications, but not to actively process such a large amount of data, so I will report back if something goes wrong.
Random Forest Cat: An ML Trading Factory
I open-sourced a multi-model, machine-learning based factory for trading strategies on GitHub. It's written in Python and is highly customizable, as it exposes a framework for configuring the pipeline via a DSL.
Currently, it comes with two pipeline configurations: one that focuses on predicting wether the price of Bitcoin in 5 minutes will be higher or lower than now (Polymarket style), and a more generic strategy that shorts or longs Bitcoin at its own discretion.
This project also represents an experiment on enabling AI agents to discover trading strategies that will be profitable with real world, live price data. Clone the project and try asking an LLM to generate a profitable trading strategy using the framework.
You can also just train your own model (or use mine) and use its signals for live trades. Beware that this is a work in progress. I've already integrated an explicit split for a the validation set, but that code is not pushed yet -- I'll probably do it today. More improvements are also on the way.
In either case, the current version of the code on GitHub works, so you can download and run it.
GitHub Repository Link: https://github.com/iluxonchik/random-forest-cat-ml-factory

Using Neural Networks To Find Imbalances In Limit Order Books
I've been working on model factory that predicts short-term asset movements. The model focuses on predicting whether the price of an asset at a future time T+c will be below or above the current asset's price at time T. c is an arbitrary constant which in my model represents the number of minutes.
Currently, it's structured to match Polymarket's 5 minute BTC up or down markets, so this model can be used for trading on those markets. In this setup, the return is binary -- you either almost double or lose the whole position (assuming an entry as within a small delta of the market open). But this model can also be easily adapted to long/short futures positions with more flexibility on entry or exit times — it would require adapting the labeler and the backtest configuration (namely the cost model and position sizing).
The first version of the model factory relied on features derived from 1 minute OCHLV data for Bitcoin. I focused on setting up a multi-model pipeline, and generalize it into a configurable DSL-like experience. I also focused on avoiding a big part of overfitting/looking forward and doing the first level of parameter optimization. I was able to obtain a small edge (≈0.54 win rate), and short-run live tests showed the model to be profitable, however I’m not very sure how resilient it is to regime changes, nor I find the computed edge sufficient (the win rate is subject to the error from the models). I also wasn’t expecting to achieve a meaningful edge with just OCHLV data, so I’m integrating limit order book (LOB) data in order to extract price movement predictive patterns from the lower level dynamics that end up determining the price.
Given that the order book drives the market price, its reasonable to assume that there is a function that expresses the relationship between the current order book state, and in which direction that state is more likely to move the price in the short-term. It’s my first time working with LOB data, so I looked for papers which explore a framework for modeling price predictions based on a multi-level LOB with price and volume data for bid and ask at each level. After filtering through several options, I settled on one titled “DeepLOB: Deep Convolutional Neural Networks for Limit Order Books” by Zihao Zhang, Stefan Zohren, and Stephen Roberts. I liked it because the authors taking care in avoiding overfitting and leaking forwarding the data, by splitting the data set into one for training, one for validation and one for testing. The model is trained on the training set, the hyperparameters are optimized on the validation set, and the verification/backtesting is done on the test set. I also wanted to integrate neural networks into the pipeline, and DeepLOB model uses a Convolutional Neural Network (CNN) and a Long Short-Term Memory (LSTM) network in its construction.
The neural networks in DeepLOB works as follows. First, the raw LOB data passes through a CNN to summarize/extract patterns from the data via filters whose weights are learned by the network. The output then goes through the inception module, which is another CNN which operates with multiple convolutional filters if different sizes to capture multiple time window patterns. Then, the resulting matrix is passed to LSTM, which is a recurrent neural network, meaning it’s able to maintain “memory” of the past state when evaluating the new state. LSTM outputs a vector, which is then multiplied by a weight matrix to produce 3 raw scores (logits), which then get mapped to probability for each one of the 3 classes via Softmax: (Up, No Change, Down), which serve as a trading signal.
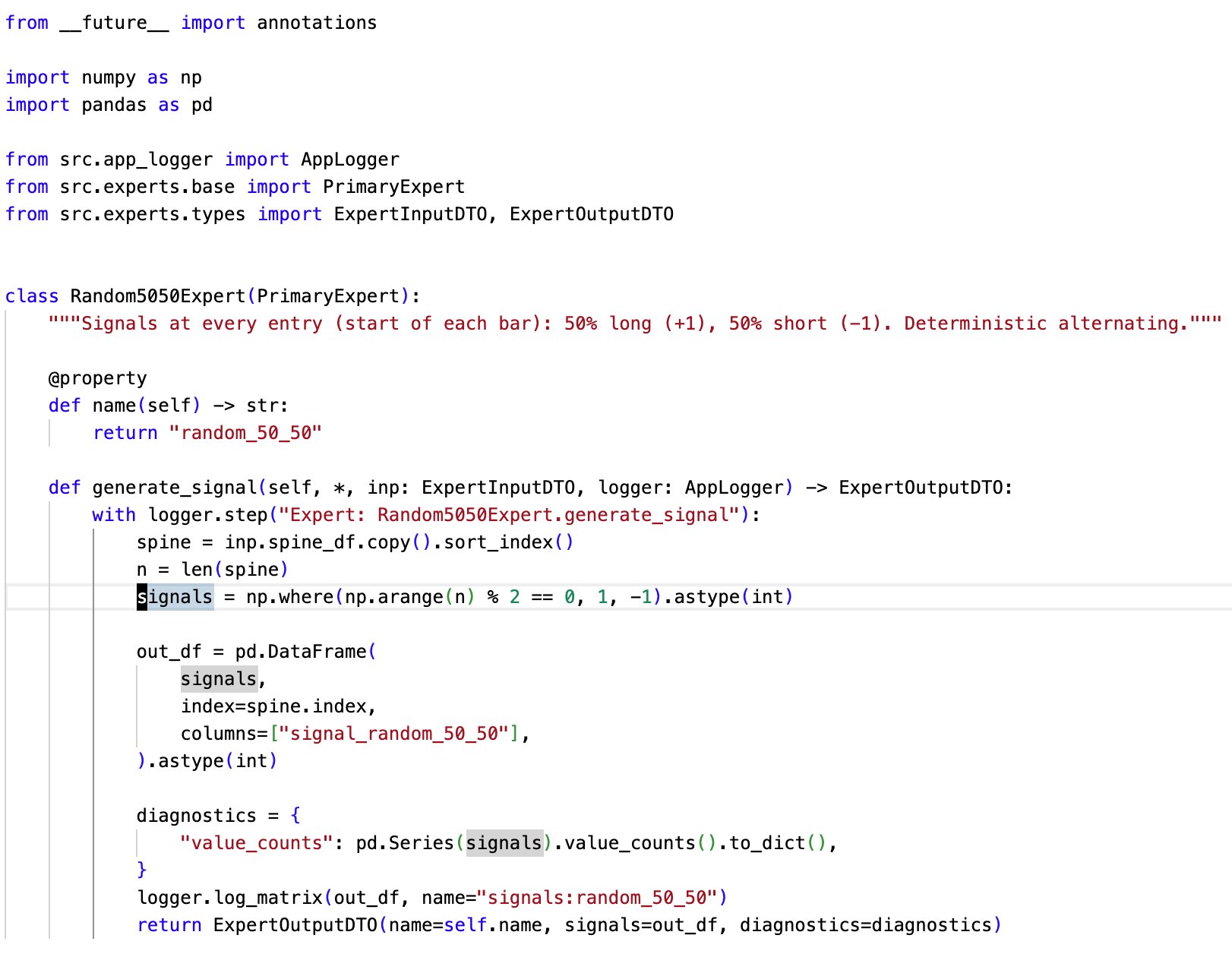
I’ll be incorporating something similar as signals/experts and/or features in the existing pipeline of my model factory. I’ll also extend the pipeline to add an additional split for the validation set to optimize the hyper parameters of the random forest. I’ll upload the code to GitHub soon, but note that it’s a work in progress.

The random forest's features have been heavily refactored. I also replaced the polymarket feature with lookahead bias (the proxy model) with a combination of other indicators.

As a result of the first step in optimizing/prioritizing the random forest’s features -- I've dropped about half of them 😁
As a result of the first step in optimizing/prioritizing the random forest’s features -- I've dropped about half of them 😁
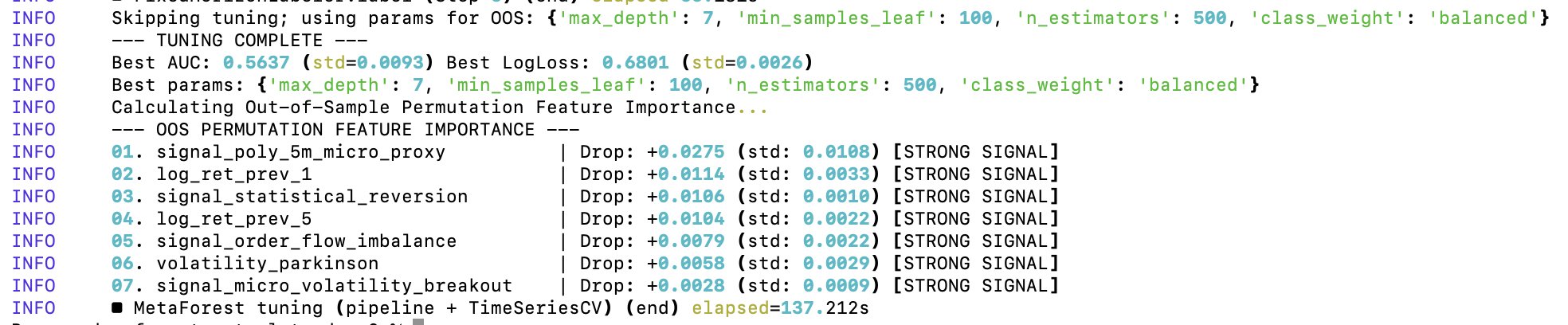
Out of Sample Permutation Feature Importance For Random Forest’s Feature Optimization
After the first level of tuning of the random forest’s parameters, it came time to optimize the features on which the random forest gets trained on. I’ve already did a minor cleanup, but I didn’t yet test for the predictive importance of each feature in the random forest.
To optimize the random forest’s features, I’m using Out of Sample Permutation Feature Importance (OOS). The OOS approach consists in three core steps:
1️⃣ Train the random forest once on the training data
2️⃣ Take out-of-sample validation data (testing data), permute the values of a single feature/values within the same column and pass them to the model trained in step 1.
3️⃣ A feature is important for the model if the model’s predictive power reduces significantly when that feature’s values are randomly shuffled.
The “out of sample” part refers to the fact that the set of data used to train the model and evaluate it after permutations is distinct, thus reducing the contribution of noise to the evaluation metrics. By default, scikit-learn uses Gini Importance to rank features by their utility to the model. Gini is a bad metric for my data because of:
➖ High cardinality bias (it has an inherent bias towards continuous variables, and some of my features are discrete)
➖ Gini importance is computed on the training data
➖ In case of two correlated features, the random forest will randomly pick one at each split, but Gini will actually divide the importance between the two
Additionally, the out-of-sample Area Under the ROC Curve (AUC) of 0.7566 is unrealistically good for predicting 5-minute Bitcoin price moves. This value implies that if you pick a random 5-minute winning window and a 5-minute losing one, my model ranks the winner window ≈76% of the time. Either I found a model that beats virtually every financial institution in existence, or there is a lookahead bias and overfitting happening in the model.
Conclusion: my meta forest — the “seconds_to_settle” feature is basically carrying the entire model 😂 So in its current state, the random forest is training almost entirely on the time of day/time to expiration. The cleanup has started.
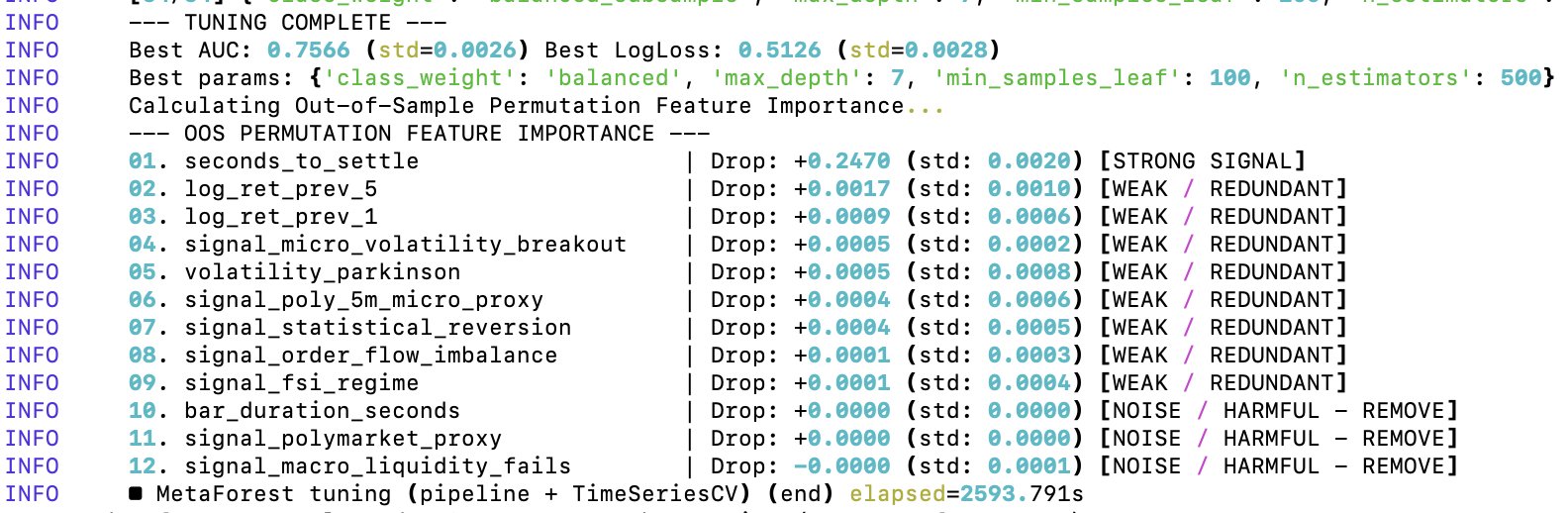
Out of Sample Permutation Feature Importance For Random Forest’s Feature Optimization
After the first level of tuning of the random forest’s parameters, it came time to optimize the features on which the random forest gets trained on. I’ve already did a minor cleanup, but I didn’t yet test for the predictive importance of each feature in the random forest.
To optimize the random forest’s features, I’m using Out of Sample Permutation Feature Importance (OOS). The OOS approach consists in three core steps:
1️⃣ Train the random forest once on the training data
2️⃣ Take out-of-sample validation data (testing data), permute the values of a single feature/values within the same column and pass them to the model trained in step 1.
3️⃣ A feature is important for the model if the model’s predictive power reduces significantly when that feature’s values are randomly shuffled.
The “out of sample” part refers to the fact that the set of data used to train the model and evaluate it after permutations is distinct, thus reducing the contribution of noise to the evaluation metrics. By default, scikit-learn uses Gini Importance to rank features by their utility to the model. Gini is a bad metric for my data because of:
➖ High cardinality bias (it has an inherent bias towards continuous variables, and some of my features are discrete)
➖ Gini importance is computed on the training data
➖ In case of two correlated features, the random forest will randomly pick one at each split, but Gini will actually divide the importance between the two
Additionally, the out-of-sample Area Under the ROC Curve (AUC) of 0.7566 is unrealistically good for predicting 5-minute Bitcoin price moves. This value implies that if you pick a random 5-minute winning window and a 5-minute losing one, my model ranks the winner window ≈76% of the time. Either I found a model that beats virtually every financial institution in existence, or there is a lookahead bias and overfitting happening in the model.
Conclusion: my meta forest — the “seconds_to_settle” feature is basically carrying the entire model 😂 So in its current state, the random forest is training almost entirely on the time of day/time to expiration. The cleanup has started.
The time to optimize hyperparameters of the random forest has come
Starting with a grid search approach

Added a connection to Binance's futures API and now I have the base learners and the random forest looking for profitable 5-minute Bitcoin trades in real time
Let's see how it goes, the model already entered its first trade. Let's see how it goes 😄

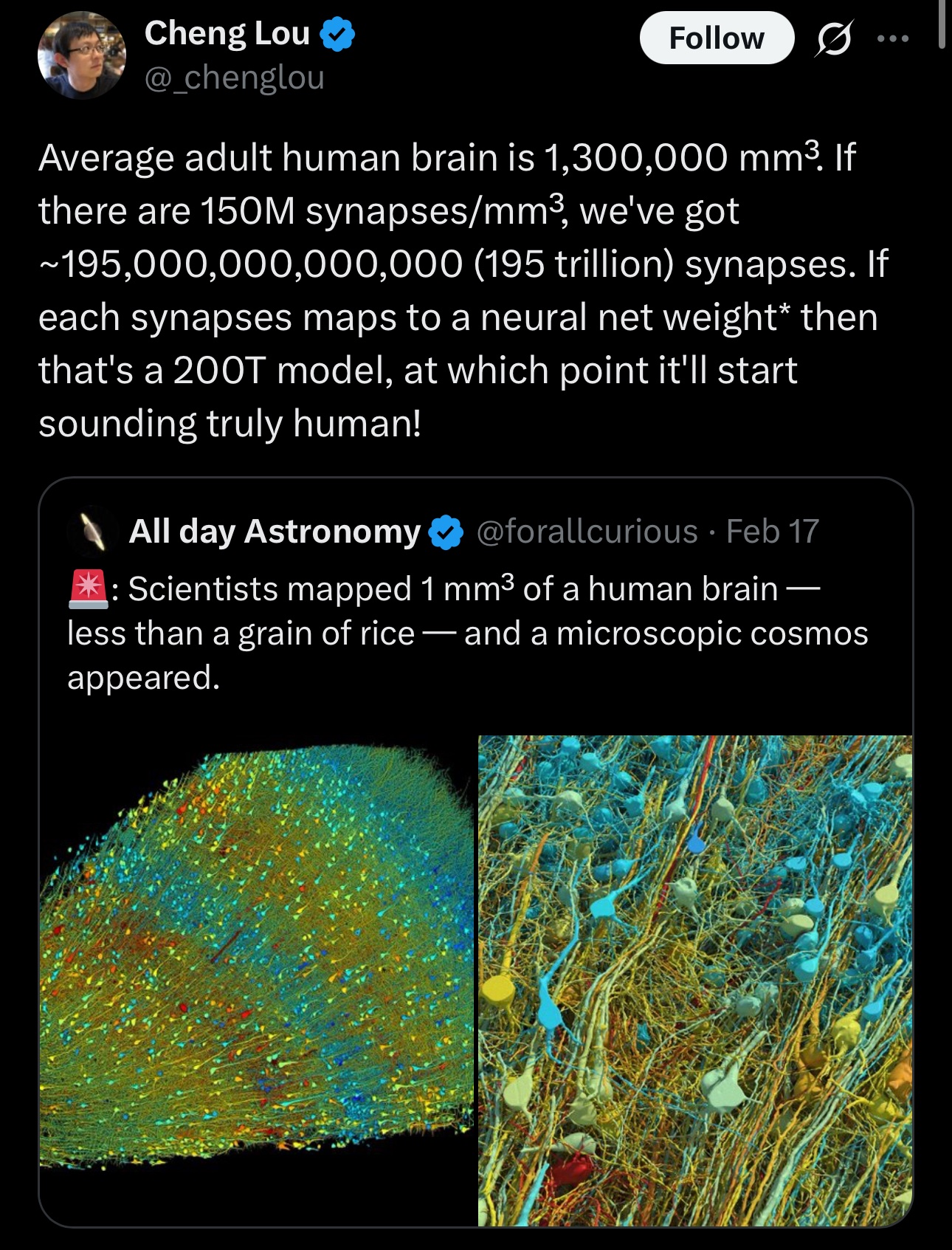
This a gross oversimplification of what it takes to replicate the human brain with AI
The post is assuming we have a model that can accurately replicate the human brain, which we don't.
200T parameter models won't solve that -- you'll still have a high model bias.
Proxy Model From Polymarket's 15 Minute Bitcoin Price
I found historical datasets for Polymarket's 15 minute up or down Bitcoin price and I think I can use this data to obtain useful signals via a proxy model. I'll start with linear regression to build a prediction model, to see if this transfer learning approach works here.
Yes, it will be overfitting, but for this signal generator it would be by design. The end goal is to find features that improve the random forest's split rules, thus further improving the win rate.
After tweaking the existing set of base learner models, the random-forest driven trading model factory continues to improve
The win rate for predicting Bitcoin's 5-minute price moves (binary) is now approaching 54%. A win rate of ≈56% should suffice to accommodate for transaction costs. Win rates over 60% is where it starts to get interesting.

Expert optimization is going well, and I'm starting to move towards the alpha in 5-minute Bitcoin price markets
I'm not claiming that the model that I currently have is meaningful (it's NOT!), but it's getting closer to interesting win rate ratios (>55%)

Currently, this is the most valued expert in my model factory pipeline
Not because it does anything useful, but precisely because it does not
The expert randomly emits positive(buy) or negative(sell) signals. This is a rough baseline for random behaviour. Very useful for the integration testing of the pipeline and identifying noise
My random forest looks much better after the clean-up
The feature matrix has been refactored to only include features from which the random forest will be able to learn more effectively. This should greatly reduce the noise
Now, it's time to optimize signals 😄

My ML model factory produced this amazing model that trades Bitcoin on 5-minute intervals, cut off at each 5th minute (very similar to Polymarket's 5 minute BTC markets) and it made over 200K trades in ≈7 months
Stats:
- 200K trades
- 6.69% profit
- 49% win rate
So I've pretty much discovered a coin flip 🤣

They say that AI agents will replace all white collar-jobs in the next 6-12 months 😄
So LLMs only have 5-11 months to learn about car washing.
This simple prompt breaks ChatGPT, DeepSeek, Qwen and Kimi. Works on Gemini though.
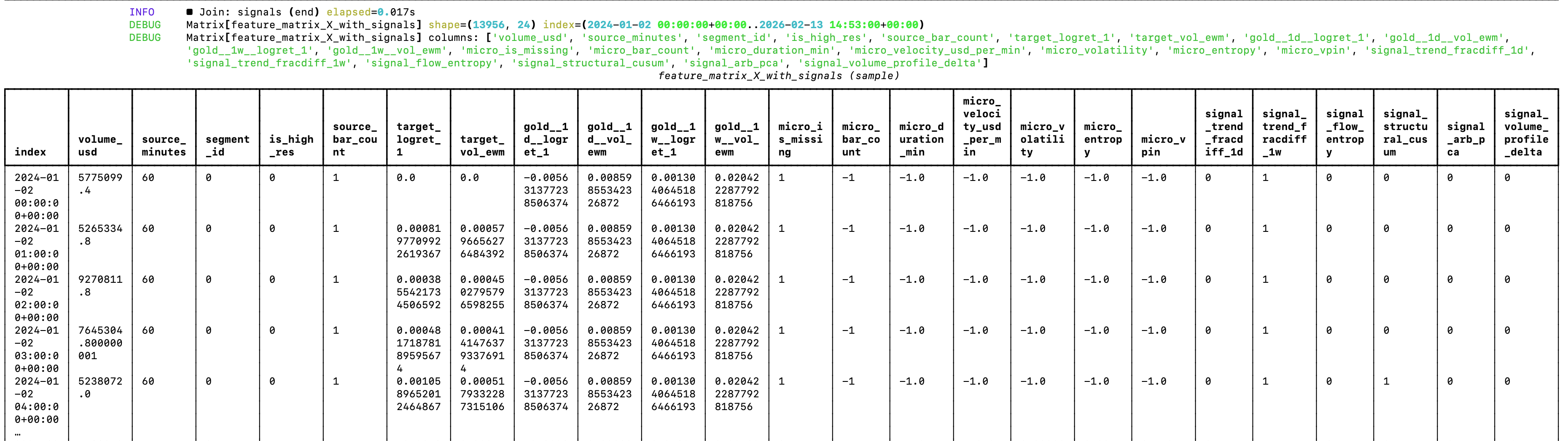
The random forest that guides my model factory needs refactoring
While the current architecture shows good prospects for generating profitable trading models, the random forest is currently a bit of a mess 😅 If you look at the image attached to the post, you can see why.
Since the random forest can’t extrapolate, features like the date and source segment will just make the forest learn on noise (it will train on association between those features, e.g. it’s not very useful to learn that volume in 2025 was higher than in 2024). But this was expected. The goal was to validate an architectural approach that could work. Now it’s time for optimizations and changes. Actually, changes before optimizations.
Another thing that I’ll get rid of is the hybrid spine for supporting data from multiple timeframes, as the model didn’t extract any meaningful alpha — and some of it has even confused the random forest. I’m sure there is way to make even with limited data, but I’ll be moving to testing it on dataset for which I have access to highly granular data (hello, Bitcoin!). So the logic of the data loader in the pipeline will be greatly simplified.
I’ll also make the labeler configurable, so that you can use the same set of features for different types of predictions. For example, you could have the “unconstrained” standard deviation labelling in the sense hat you can enter and exit the position at any time, to constrained logic scenarios such as the ones of Polymarket’s 5-minute price predictions on Bitcoin, where you can only enter a position at specific times, and the resolution happens at specific times (e.g. at the end of every 5th minute of the day, starting from 0).
The core logic of the ML pipeline remans the same.
One idea for vibe-coding profitable trading strategies is to strictly define a pipeline of your ML strategy factory, and restrict your AI agent to only write code within your tightly-defined framework.
I'm currently exploring this. To add a new signal, the agent will need to extend this contract.
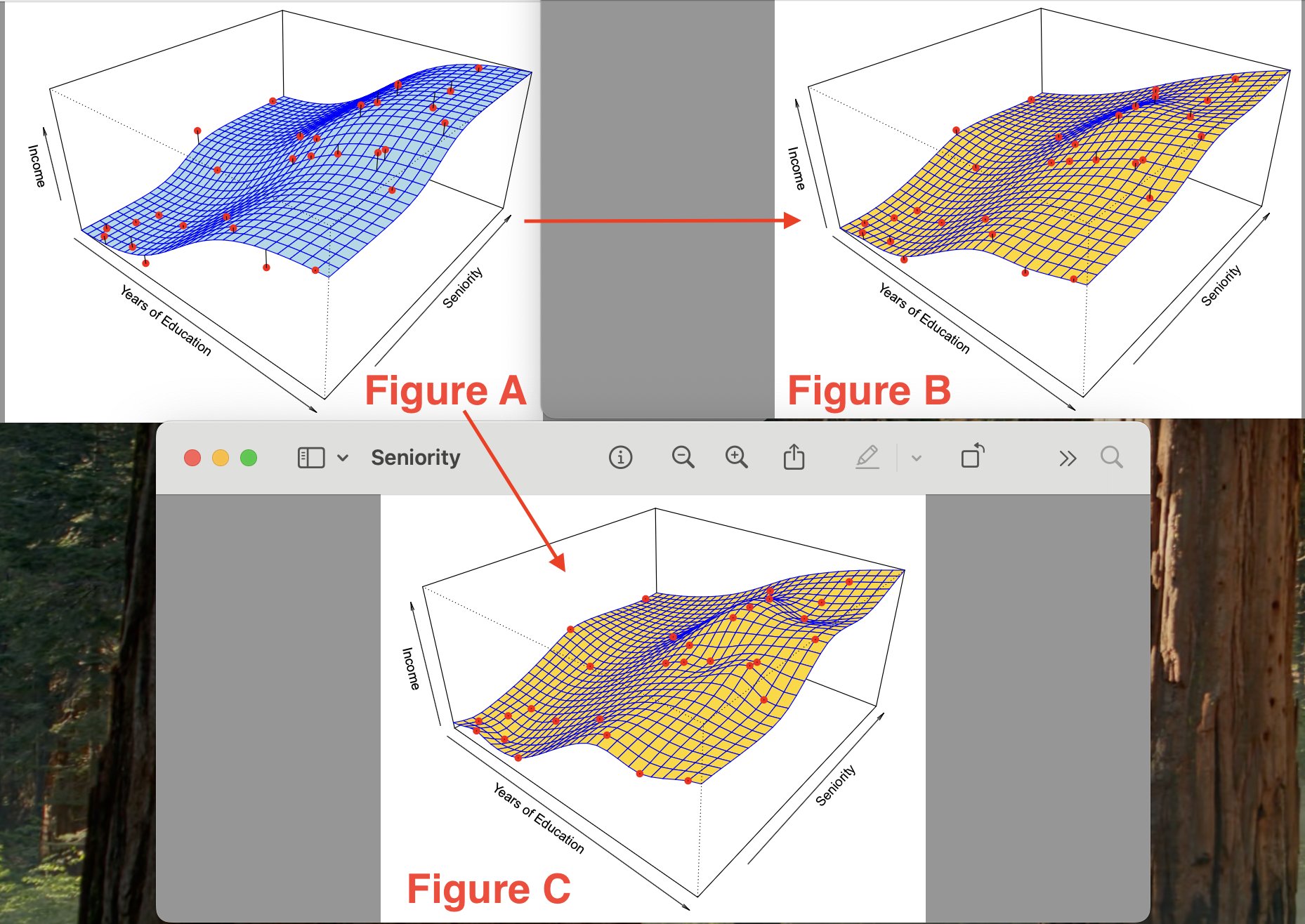
Overfitting In Machine Learning Models Visualized
I came across the visualization of 3 functions which demonstrate how a model can become overfit to noise.
So we are trying to estimate the function whose graph visualization is shown in figure A. In A you see the true underlying function representation. Figures B and C are estimates for the true function shown in Figure A. In Figures B and C, a thin-plate spline fit is used to approximate the function shown in A. To obtain the function/model in Figure C, a smaller level of smoothness was used than in Figure B (less smoothing means more flexibility/effective degrees of freedom).
Figure B approximates the function pretty well, while Figure C fits the training data *perfectly*, with ZERO errors on the training data (in figure C you can see that all of the red points are on the yellow surface). However, you notice that the surface in figure C is a lot more variable/wiggly than in figure A - this is because in the process of constructing the function model in Figure C - we overfit on the noise in the training set!
So by overfitting you are making your model extremely sensitive/adapted to the training data, and the model ends up learning from the noise instead of actual signals. Regarding a machine-learning approach to trading/finance - this is how you get >90% success rate while backtesting your model, but around random performance with novel real-world price data.
You have to remember than beyond trivial use-cases, your models are never going to be perfect — and if they are, you are probably overfitting. You have to remember that any ML model that you construct *NEVER* perfect, due to the presence of irreducible errors, bias and variance.
Okay I found another source of overfitting/data leakage in my trading ML factory 😁
The triple barrier label is computed at *position close time*, which is determined by which deviation from price returns hits first (upper bound, lower bound or timeout). The training set was including everything until a specific date, *BUT* many positions before that date close in the future - after the training cutoff date. I only got a few confirmed leaks from my run - but still overfitting.
These series of posts I’ve been making, provide you with a small practical glance into why mere backtest performance is not an indication of absolutely NOTHING. This is also what essentially goes into constructing an automated, machine-learning driven trading strategy (or rather a factory for those!). It’s very easy to overfit.
There are many large-following accounts on X/Twitter that post about the strategies that they discovered, with impressive performance on historical data. Usually those same accounts have ulterior motives, such as selling courses or access to trading signal groups. Be aware that their backtest results are NOT an indication that their strategy will work in a real-world scenario. As a general rule, if those pay-to-access strategies really performed that well with novel price data - the individuals running those strategies would be much better off operating on a fee-basis (i.e. they charge a percentage of returns on your capital, rather than a fixed fee.

My trading ML factory yielded ≈22% return on gold on a daily timeframe, which is almost a double of gold's return in the same time period (≈12%)
This was after running in on price data of gold futures most recent drawdown from ≈$5600. The model yielded its largest returns by longing the pullbacks during the correction and closing the positions at the right time (the exit logic is based on deviations from price returns). This is very interesting, as it could be an indication of model's utility during drawdowns. Its largest loss was also during the same event frame, but I believe that can be greatly optimized with model parameters and thresholds (which I haven’t optimized at all yet).
The entry/exit times are imprecise, because the strategy is based on volume dollar bars sampling, which I'm extracting/approximating from OCHLV data from TradingView.
Entry/exit decisions are driven by a random forest, which learns from the signals of various "experts”, and a tripple-barrier outcome of those signals. In practice, the experts are just Python functions which perform statistical analysis on the dollar volume feature matrix containing combined price history from various timeframes, and output a buy(1), sell(-1) or do nothing(0) signal. Then, the buy and sell signals from experts are passed to a random forest in a matrix, which then “learns” which combination of expert calls yields the most correct returns. The experts only produce position entry signals, each position is then closed based on standard deviation of price returns (intuitively: the position is closed when the price exhibits an “unusual” perceptual move, either up or down).
This trading ML factory was designed to work under significant constraints of historical price data. I limited it to the one available for export in TradingView. For example, 1 hour candle data only goes back a little over 2 years. In principle, there is little alpha to be extracted from here, but I was able to mitigate it by following a “hybrid spine” approach, where multiple timeframes are combined statistically and made available in the matrix passed to the random forest. More granular OCHLV data is scarce (e.g. the 1 minute OCHLV data that I have available for gold futures, goes back less than a month, and there are some continuity gaps in it), however it is still useful to provide some micromarket structure int terms of volume that the random forest can rely on. As such, the factory performs best on higher timeframes (4h and above).
The ML factory learns and predicts based on the prices of multiple assets (and the ratios between them). At the moment, it computes our to gold, silver and copper futures OCHLV data. But it’s designed to be dynamically extendable by adding CSVs with new asset price data.
Currently, I’m very much at the prototyping/exploratory phase with this project, so I don’t have the code publicly available yet. If you want access to the code, just reach out to me. I’m not claiming in any way that it will consistently yield >20% returns, and I understand that the trade count, trading data set granularity and backtesting timeframe are not sufficient for a strong statistical confidence in evaluating the quality of the model factory, but I am claiming that it provides a starting point for directing the factory’s approach. Also, trading costs, slippage, position sizing are not accounted for. Even with limited historical data, I believe that a careful selection of experts can yield profitable automated strategies.

My trading ML factory yielded ≈22% return on gold on a daily timeframe, which is almost a double of gold's return in the same time period (≈12%)
This was after running in on price data of gold futures most recent drawdown from ≈$5600. The model yielded its largest returns by longing the pullbacks during the correction and closing the positions at the right time (the exit logic is based on deviations from price returns). This is very interesting, as it could be an indication of model's utility during drawdowns. Its largest loss was also during the same event frame, but I believe that can be greatly optimized with model parameters and thresholds (which I haven’t optimized at all yet).
The entry/exit times are imprecise, because the strategy is based on volume dollar bars sampling, which I'm extracting/approximating from OCHLV data from TradingView.
Entry/exit decisions are driven by a random forest, which learns from the signals of various "experts”, and a tripple-barrier outcome of those signals. In practice, the experts are just Python functions which perform statistical analysis on the dollar volume feature matrix containing combined price history from various timeframes, and output a buy(1), sell(-1) or do nothing(0) signal. Then, the buy and sell signals from experts are passed to a random forest in a matrix, which then “learns” which combination of expert calls yields the most correct returns. The experts only produce position entry signals, each position is then closed based on standard deviation of price returns (intuitively: the position is closed when the price exhibits an “unusual” perceptual move, either up or down).
This trading ML factory was designed to work under significant constraints of historical price data. I limited it to the one available for export in TradingView. For example, 1 hour candle data only goes back a little over 2 years. In principle, there is little alpha to be extracted from here, but I was able to mitigate it by following a “hybrid spine” approach, where multiple timeframes are combined statistically and made available in the matrix passed to the random forest. More granular OCHLV data is scarce (e.g. the 1 minute OCHLV data that I have available for gold futures, goes back less than a month, and there are some continuity gaps in it), however it is still useful to provide some micromarket structure int terms of volume that the random forest can rely on. As such, the factory performs best on higher timeframes (4h and above).
The ML factory learns and predicts based on the prices of multiple assets (and the ratios between them). At the moment, it computes our to gold, silver and copper futures OCHLV data. But it’s designed to be dynamically extendable by adding CSVs with new asset price data.
Currently, I’m very much at the prototyping/exploratory phase with this project, so I don’t have the code publicly available yet. If you want access to the code, just reach out to me. I’m not claiming in any way that it will consistently yield >20% returns, and I understand that the trade count, trading data set granularity and backtesting timeframe are not sufficient for a strong statistical confidence in evaluating the quality of the model factory, but I am claiming that it provides a starting point for directing the factory’s approach. Also, trading costs, slippage, position sizing are not accounted for. Even with limited historical data, I believe that a careful selection of experts can yield profitable automated strategies.
So I solved the overfitting issue, and as I suspected backtest data was leaking into the training set
In 13 trading days it yields ≈12% with gold on an hourly timeframe target. For silver it goes up to ≈30% (expectedly)
I'm going to add 15m, 5m and 1m data to see how it performs during the drawdown

My random-forest guided meta model factory discovered a trading strategy which profits 87773.98% in the past 7 years
There is definitely no overfitting here 😂

Don't Be Fooled By Backtest Performance
I've been coming accross of posts on X from accounts showcasing 70%+ returns when backtesting their vibe-coded trading strategies. Don't be misguidaded by those numbers and claims.
Most likely it performs well on historical data, but is random at best with new data.Agents are not that good at developing profitable trading strategies, as they tend to stick 'default' statistical measures like RSI and hope for the best 😄 If it was that easy - everyone would do it, thus erasing any alpha
These vibe-coded models most likely overfitting
No AGI With LLMs In Their Current Form.
Generative models are just one type of models in ML. Neither self-driving cars, nor inference about financial data primarily rely on generative models. Perhaps you can have LLM program that logic on the go, but that would require the LLM to effectively dominate those tasks (i.e. effectively become good at driving a car and being able to build sound financial models via a programming language), and given the probabilistic nature of the inference I don’t think we can have LLMs and agents fully taking over these critical areas. Regarding the probabilistic nature, I’m specifically referring the unsecured/unparameterized probability - it’s hard to modulate the potential error.
Right now, agent setups are very good at boilerplate, repeatable code - and most of the code is like that. Most of software development is already abstracted by various frameworks, and a lot of the softwares do very similar tasks and are implemented in similar ways, following specific patterns. Anecdotally, think of a generic SaaS - there are several competing products that do basically the same thing, because they solve a common problem. Agents/LLMs are already great at predicting code of which they have a lot of examples in their training set. This alone, is a massive productivity boost, especially if you are prototyping/iterating.
To give a more concrete answer, the current tech would probably top out at multi-agent, multi-model and some form of DSL(s). So you would have multiple agents, some of them using distinct models. For example, one model for planning, another model for writing code, another model for debugging, etc. The DSLs would be used for both: customizing agents and models (input) and the model would output the code in a DSL (output). So when you ask the model to generate code, it would output it in a higher-level programming language/DSL, and then that one would either be compiled down/translated into a different target, wether that is machine code or a programming language like Python. The DSL design would be optimized for this “generative development” - in practice it will make things like math-induced security issues more difficult for LLMs to make (e.g. the DSL forces the LLM to use pre-defined cryptographic primitives, and at compilation time type metadata is associated to enforce its correct usage across schemes). So at this tech’s peak, the LLMs probably won’t be outputting their code in directly Python. I don’t mean that this is the peak for generative models or ML field as a whole, but for the current state of the tech and the approaches it uses.
Before the tech tops out, however, I think there will be a security issue at scale, followed by an increased focus on security of agents and the the inferred code. Since many products will be using the same models to generate code, the same flawed security patterns will arise in many places, and it will be “easy” to exploit them at scale. Even with detailed instructions, SOTA models still generate vulnerabilities. Even though most of the code is fine, it takes one small issue in a sensitive place to compromise the system - and if you write any non-trivial code with LLMs, you will run into them. I’ve encountered a lot of this issues myself, and in the code that I’ve reviewed from other developers who wrote their code with LLMs. Proper context helps a lot, but it doesn’t resolve the probabilistic nature of the output.
Regarding getting closer to human-like functionality, it will almost certainly require other ML schemes/approaches in addition to what we have now and further refining and combination of existing approaches. I think we will soon go into meta-models, where a model internally uses other models/sub models to produce the output (in its simplest form, think of a random forest that “choses” the most appropriate sub-model to run or the output which one of the sub-model’s outputs to use for the next step) - this can help mitigate some of the risks arising from the probabilistic nature of the inference. That would require coordinated, specialized agents, powered by meta-models.
Where I think we have a lot to still to gain with the current tech, even if its progress freezes, is education. LLMs provide a novel way to interact with digital information, you can do it in the same way that you would interact with another human - via spoken language. Being able to formulate your very specific questions, in your very specific way and usually getting a correct answer to it still amazes me to this day. If you combine generative models with VR, you get a whole new dimension of experiencing information, allowing to learn more effectively.