My Thoughts
Short-form commentary on macro, market structure, commodities, Bitcoin, crypto markets, and AI.

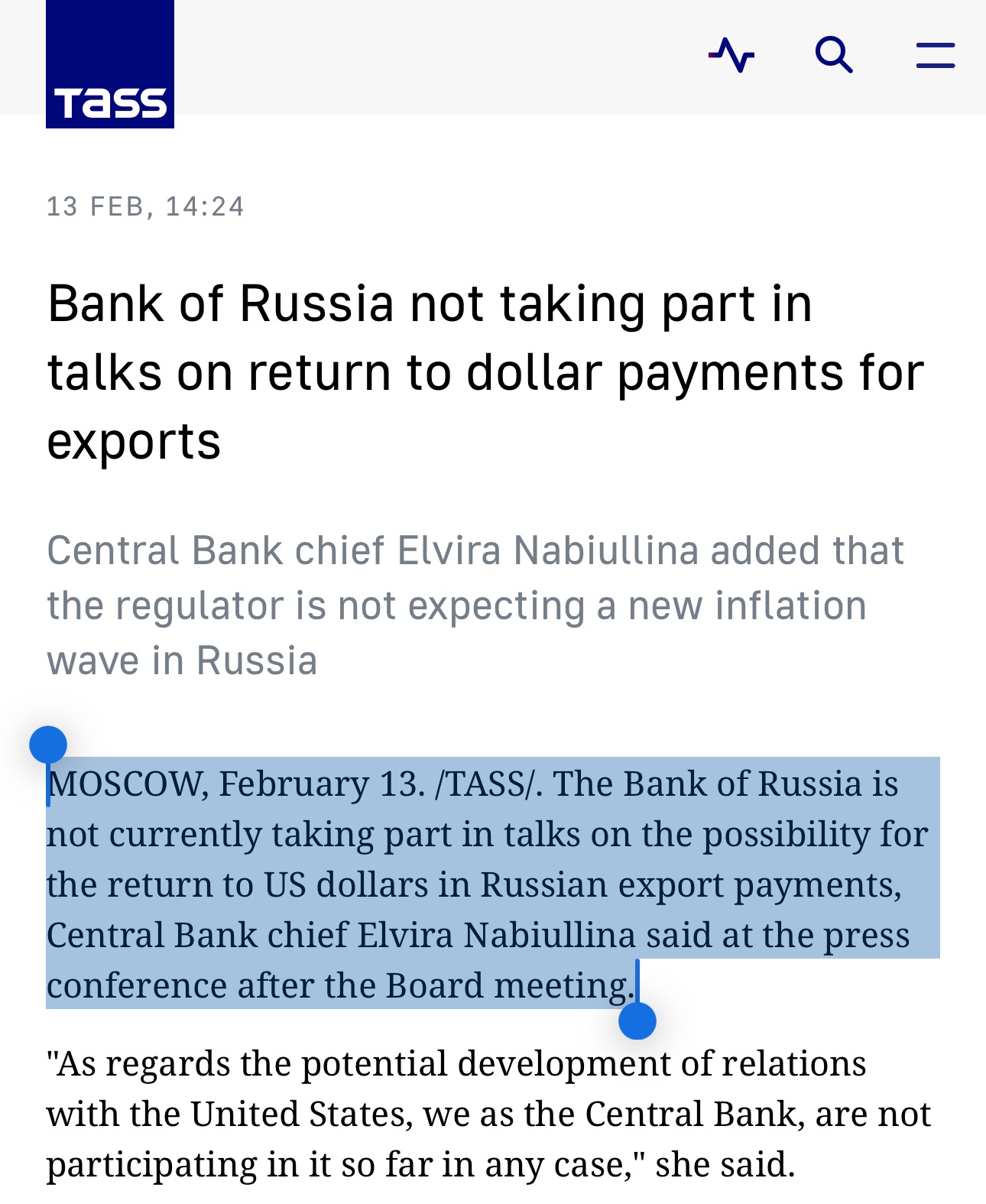
Central Bank of Russia Denies Return to USD Payments
Just like I argued yesterday, claims by Bloomberg and other financial media suggesting that Russia is to return to USD settlement were misguided/wrong.
Not only those claims lacked factual basis, but also didn't make sense in terms of a macro picture.
Remember: just because a large-following news source claims something, it doesn't make it true. And do not discount for the existence of coordinated campaigns with ulterior motives. It doesn't have to be necessarily market manipulation -- just the engagement on its own can be a strong motivator.
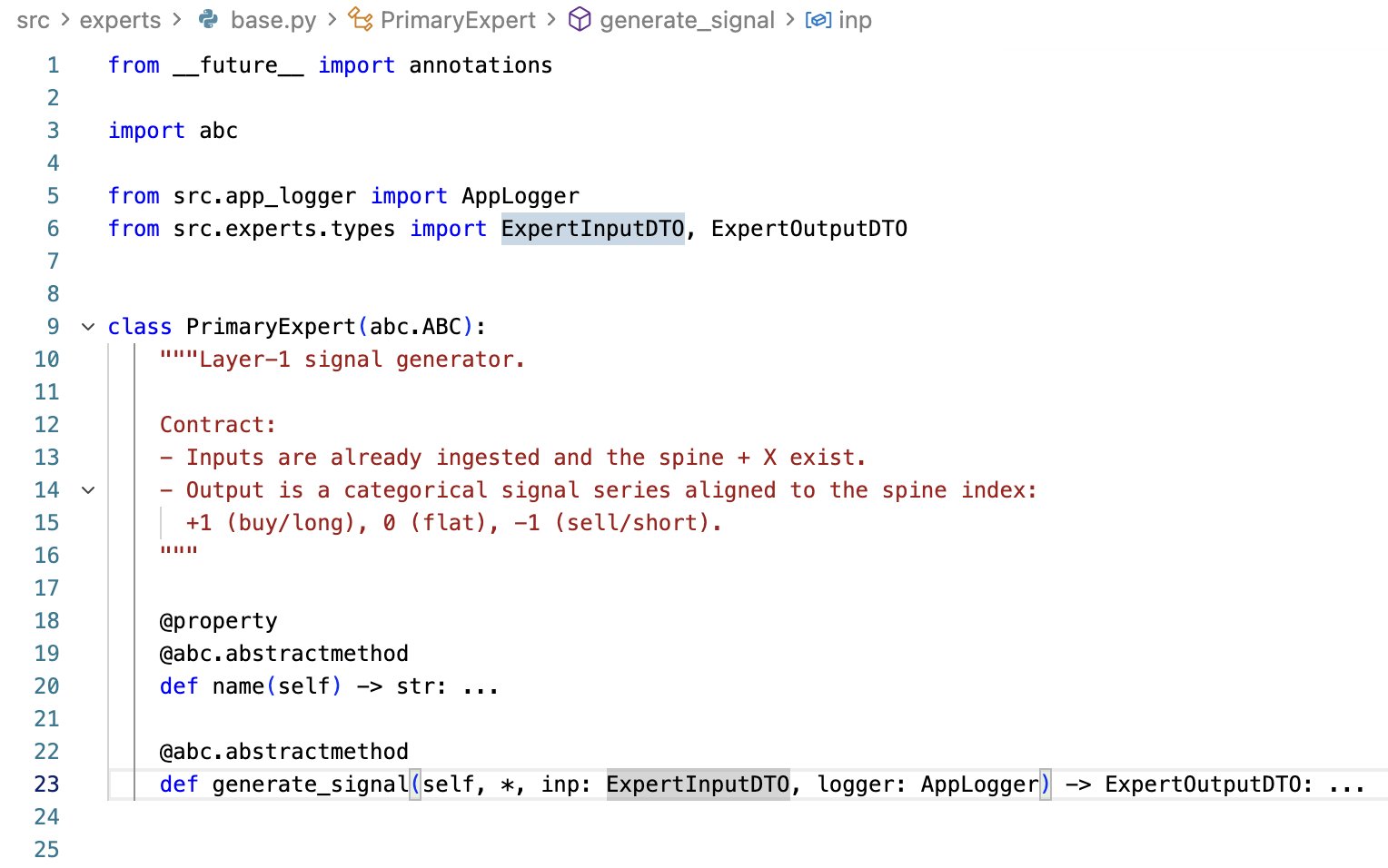
One idea for vibe-coding profitable trading strategies is to strictly define a pipeline of your ML strategy factory, and restrict your AI agent to only write code within your tightly-defined framework.
I'm currently exploring this. To add a new signal, the agent will need to extend this contract.
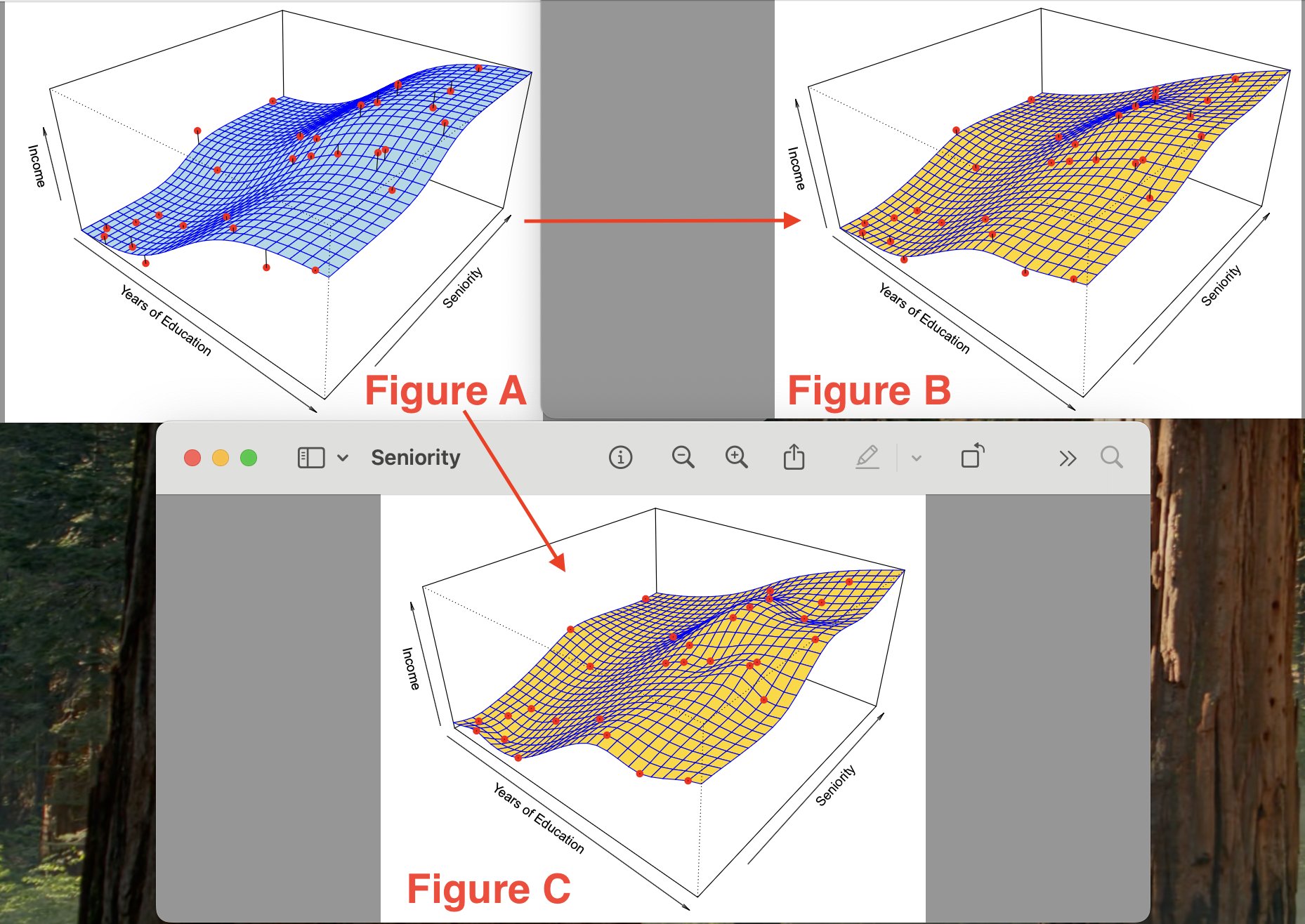
Overfitting In Machine Learning Models Visualized
I came across the visualization of 3 functions which demonstrate how a model can become overfit to noise.
So we are trying to estimate the function whose graph visualization is shown in figure A. In A you see the true underlying function representation. Figures B and C are estimates for the true function shown in Figure A. In Figures B and C, a thin-plate spline fit is used to approximate the function shown in A. To obtain the function/model in Figure C, a smaller level of smoothness was used than in Figure B (less smoothing means more flexibility/effective degrees of freedom).
Figure B approximates the function pretty well, while Figure C fits the training data *perfectly*, with ZERO errors on the training data (in figure C you can see that all of the red points are on the yellow surface). However, you notice that the surface in figure C is a lot more variable/wiggly than in figure A - this is because in the process of constructing the function model in Figure C - we overfit on the noise in the training set!
So by overfitting you are making your model extremely sensitive/adapted to the training data, and the model ends up learning from the noise instead of actual signals. Regarding a machine-learning approach to trading/finance - this is how you get >90% success rate while backtesting your model, but around random performance with novel real-world price data.
You have to remember than beyond trivial use-cases, your models are never going to be perfect — and if they are, you are probably overfitting. You have to remember that any ML model that you construct *NEVER* perfect, due to the presence of irreducible errors, bias and variance.
It's not about whether you have a use for the land you own, it's about whether someone else has or will
By owning land, at the very least, you are holding this asset for someone else's future use, and you get compensated for that service.
Land ownership comes with a set of requirements and obligations: taxes, legal work, liquidity, etc. A future buyer would be paying for those costs directly and indirectly.
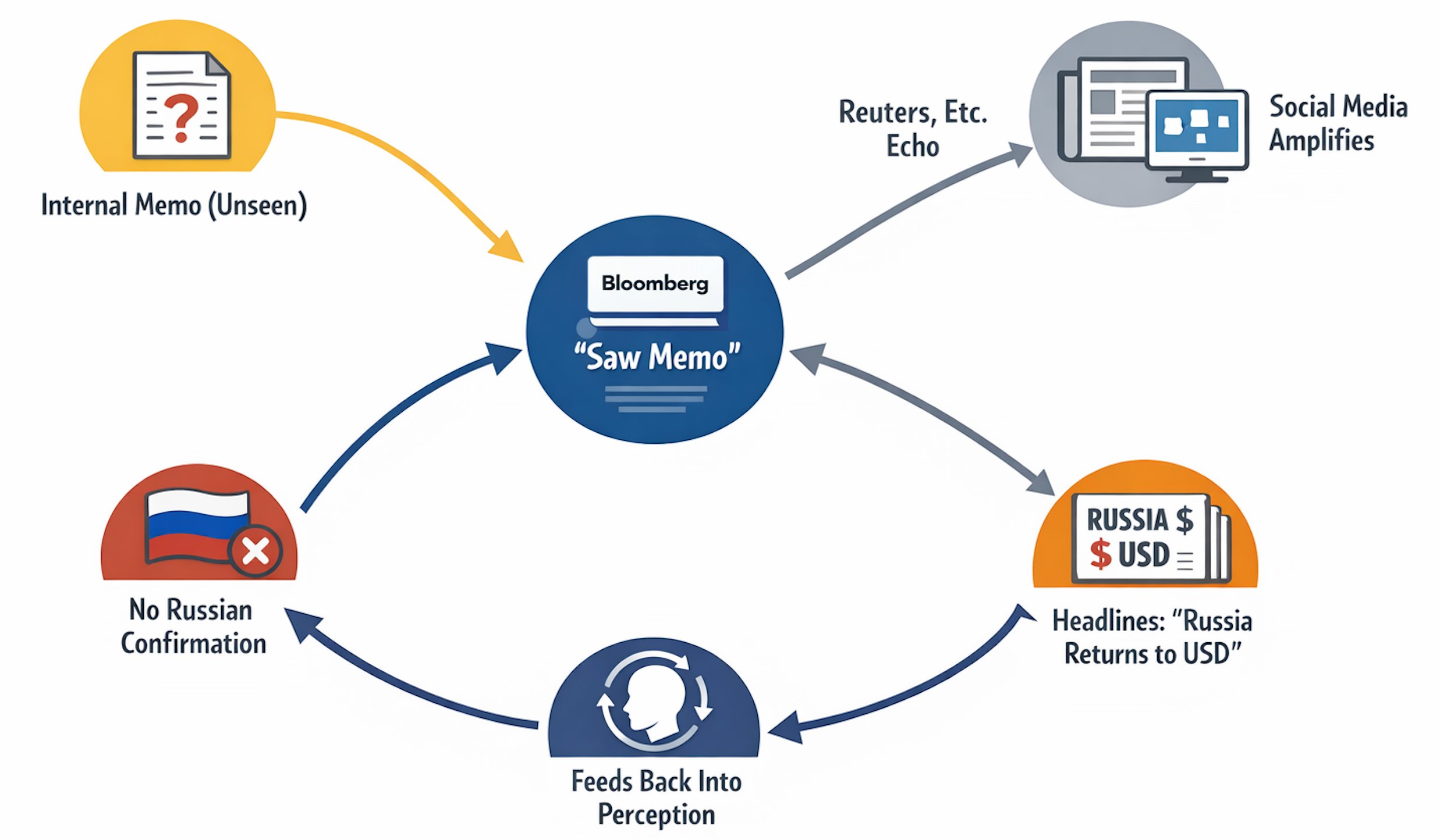
Fact-Check: Russia Moving Back To USD?
Today, financial news sources are flooded with information claiming that Russia is planning a return to the US dollar, as a part of wider strategic-economic partnership with Trump, but it is true?
Reportedly, Russia’s move back to USD comes packaged with other economic cooperation points, mostly around commodities (fossil fuels in particular). This is what mainstream financial media like Bloomberg, Reuters and accounts with millions followers on X have been spreading viciously today, many of which frame this as the end of BRICS and/or the successful policies of the Trump administration.
What bothered me, is that none of them seem to clearly outline the source, mostly citing it as “Bloomberg reports”. This brings the obvious question: what sources did Bloomberg use in making this report? Well, reports regarding “Russia returning to USD settlement system” arise from an "internal Kremlin memo" that Bloomberg supposedly had access to. No further information is provided regarding the nature of this memo. No Russian state sources confirmed this information. It’s also not clear why Russia would seemingly sidestep their main strategic partner - China with this move (especially for those claiming the end of BRICS). So we are in a situation where Bloomberg claims they’ve seen X, and X gets spread as a fact, based on the claim by Bloomberg.
Major news sources are reposting this memo and framing it as Russias’s return to USD without stepping back to analyze it critically. Why would Russia, which gradually moved away from USD throughout the last 20 years, would suddenly reverse their policy to accept USD as the preferred medium of settlement? Would Russia trade in USD again — of course, I don’t believe they ever refused that.
Eventually, I fully expect Russia to be reintegrated back into international trade, and that includes trading in USD. I’ve written about that many times. What I do not expect is the Central Bank of Russia to dramatically increase USD instruments in their FX reserves. They were already sanctioned once, and that will remain a perpetual risk. Russia has successfully moved away from the U.S. Dollar, by replacing it with gold and renminbi, and they don’t have a serious dependency on US trade. If you think that you will have American companies owning Russian fossil fuel production in the near future you are mistaken.
So my take on this: claims of Russia’s return to USD settlement are overblown. This looks more like a coordinated campaign than something with real substance.
Why would anyone take US job number reports seriously at this point is beyond me
They keep getting revised down. Those who celebrate when new job numbers are above expectations, are the same who remain quiet once they get revised down
The cycle is as follows:
1. Release numbers surpassing expectations
2. Coordinated celebration in praising the US economy and current administration
3. Numbers get revised down
4. *crickets*
At this point you should be used to this playbook.
Okay I found another source of overfitting/data leakage in my trading ML factory 😁
The triple barrier label is computed at *position close time*, which is determined by which deviation from price returns hits first (upper bound, lower bound or timeout). The training set was including everything until a specific date, *BUT* many positions before that date close in the future - after the training cutoff date. I only got a few confirmed leaks from my run - but still overfitting.
These series of posts I’ve been making, provide you with a small practical glance into why mere backtest performance is not an indication of absolutely NOTHING. This is also what essentially goes into constructing an automated, machine-learning driven trading strategy (or rather a factory for those!). It’s very easy to overfit.
There are many large-following accounts on X/Twitter that post about the strategies that they discovered, with impressive performance on historical data. Usually those same accounts have ulterior motives, such as selling courses or access to trading signal groups. Be aware that their backtest results are NOT an indication that their strategy will work in a real-world scenario. As a general rule, if those pay-to-access strategies really performed that well with novel price data - the individuals running those strategies would be much better off operating on a fee-basis (i.e. they charge a percentage of returns on your capital, rather than a fixed fee.

My trading ML factory yielded ≈22% return on gold on a daily timeframe, which is almost a double of gold's return in the same time period (≈12%)
This was after running in on price data of gold futures most recent drawdown from ≈$5600. The model yielded its largest returns by longing the pullbacks during the correction and closing the positions at the right time (the exit logic is based on deviations from price returns). This is very interesting, as it could be an indication of model's utility during drawdowns. Its largest loss was also during the same event frame, but I believe that can be greatly optimized with model parameters and thresholds (which I haven’t optimized at all yet).
The entry/exit times are imprecise, because the strategy is based on volume dollar bars sampling, which I'm extracting/approximating from OCHLV data from TradingView.
Entry/exit decisions are driven by a random forest, which learns from the signals of various "experts”, and a tripple-barrier outcome of those signals. In practice, the experts are just Python functions which perform statistical analysis on the dollar volume feature matrix containing combined price history from various timeframes, and output a buy(1), sell(-1) or do nothing(0) signal. Then, the buy and sell signals from experts are passed to a random forest in a matrix, which then “learns” which combination of expert calls yields the most correct returns. The experts only produce position entry signals, each position is then closed based on standard deviation of price returns (intuitively: the position is closed when the price exhibits an “unusual” perceptual move, either up or down).
This trading ML factory was designed to work under significant constraints of historical price data. I limited it to the one available for export in TradingView. For example, 1 hour candle data only goes back a little over 2 years. In principle, there is little alpha to be extracted from here, but I was able to mitigate it by following a “hybrid spine” approach, where multiple timeframes are combined statistically and made available in the matrix passed to the random forest. More granular OCHLV data is scarce (e.g. the 1 minute OCHLV data that I have available for gold futures, goes back less than a month, and there are some continuity gaps in it), however it is still useful to provide some micromarket structure int terms of volume that the random forest can rely on. As such, the factory performs best on higher timeframes (4h and above).
The ML factory learns and predicts based on the prices of multiple assets (and the ratios between them). At the moment, it computes our to gold, silver and copper futures OCHLV data. But it’s designed to be dynamically extendable by adding CSVs with new asset price data.
Currently, I’m very much at the prototyping/exploratory phase with this project, so I don’t have the code publicly available yet. If you want access to the code, just reach out to me. I’m not claiming in any way that it will consistently yield >20% returns, and I understand that the trade count, trading data set granularity and backtesting timeframe are not sufficient for a strong statistical confidence in evaluating the quality of the model factory, but I am claiming that it provides a starting point for directing the factory’s approach. Also, trading costs, slippage, position sizing are not accounted for. Even with limited historical data, I believe that a careful selection of experts can yield profitable automated strategies.

My trading ML factory yielded ≈22% return on gold on a daily timeframe, which is almost a double of gold's return in the same time period (≈12%)
This was after running in on price data of gold futures most recent drawdown from ≈$5600. The model yielded its largest returns by longing the pullbacks during the correction and closing the positions at the right time (the exit logic is based on deviations from price returns). This is very interesting, as it could be an indication of model's utility during drawdowns. Its largest loss was also during the same event frame, but I believe that can be greatly optimized with model parameters and thresholds (which I haven’t optimized at all yet).
The entry/exit times are imprecise, because the strategy is based on volume dollar bars sampling, which I'm extracting/approximating from OCHLV data from TradingView.
Entry/exit decisions are driven by a random forest, which learns from the signals of various "experts”, and a tripple-barrier outcome of those signals. In practice, the experts are just Python functions which perform statistical analysis on the dollar volume feature matrix containing combined price history from various timeframes, and output a buy(1), sell(-1) or do nothing(0) signal. Then, the buy and sell signals from experts are passed to a random forest in a matrix, which then “learns” which combination of expert calls yields the most correct returns. The experts only produce position entry signals, each position is then closed based on standard deviation of price returns (intuitively: the position is closed when the price exhibits an “unusual” perceptual move, either up or down).
This trading ML factory was designed to work under significant constraints of historical price data. I limited it to the one available for export in TradingView. For example, 1 hour candle data only goes back a little over 2 years. In principle, there is little alpha to be extracted from here, but I was able to mitigate it by following a “hybrid spine” approach, where multiple timeframes are combined statistically and made available in the matrix passed to the random forest. More granular OCHLV data is scarce (e.g. the 1 minute OCHLV data that I have available for gold futures, goes back less than a month, and there are some continuity gaps in it), however it is still useful to provide some micromarket structure int terms of volume that the random forest can rely on. As such, the factory performs best on higher timeframes (4h and above).
The ML factory learns and predicts based on the prices of multiple assets (and the ratios between them). At the moment, it computes our to gold, silver and copper futures OCHLV data. But it’s designed to be dynamically extendable by adding CSVs with new asset price data.
Currently, I’m very much at the prototyping/exploratory phase with this project, so I don’t have the code publicly available yet. If you want access to the code, just reach out to me. I’m not claiming in any way that it will consistently yield >20% returns, and I understand that the trade count, trading data set granularity and backtesting timeframe are not sufficient for a strong statistical confidence in evaluating the quality of the model factory, but I am claiming that it provides a starting point for directing the factory’s approach. Also, trading costs, slippage, position sizing are not accounted for. Even with limited historical data, I believe that a careful selection of experts can yield profitable automated strategies.
So I solved the overfitting issue, and as I suspected backtest data was leaking into the training set
In 13 trading days it yields ≈12% with gold on an hourly timeframe target. For silver it goes up to ≈30% (expectedly)
I'm going to add 15m, 5m and 1m data to see how it performs during the drawdown

My random-forest guided meta model factory discovered a trading strategy which profits 87773.98% in the past 7 years
There is definitely no overfitting here 😂

Many underestimate the smart contract, blockchain protocol and oracle risks in Polymarket
Polymarket positions are always far from "risk free". This is also why liquidity on the platform is skewed with ample arbitrage opportunities.
There is no free lunch
So the yield on USDT on AAVE is below 2%. USD Money markets currently yield ≈3.5%
Why would you take on much more risk on-chain for a smaller return?
You are much less likely to lose your funds in a regulated venue than on an Ethereum-based derivative.
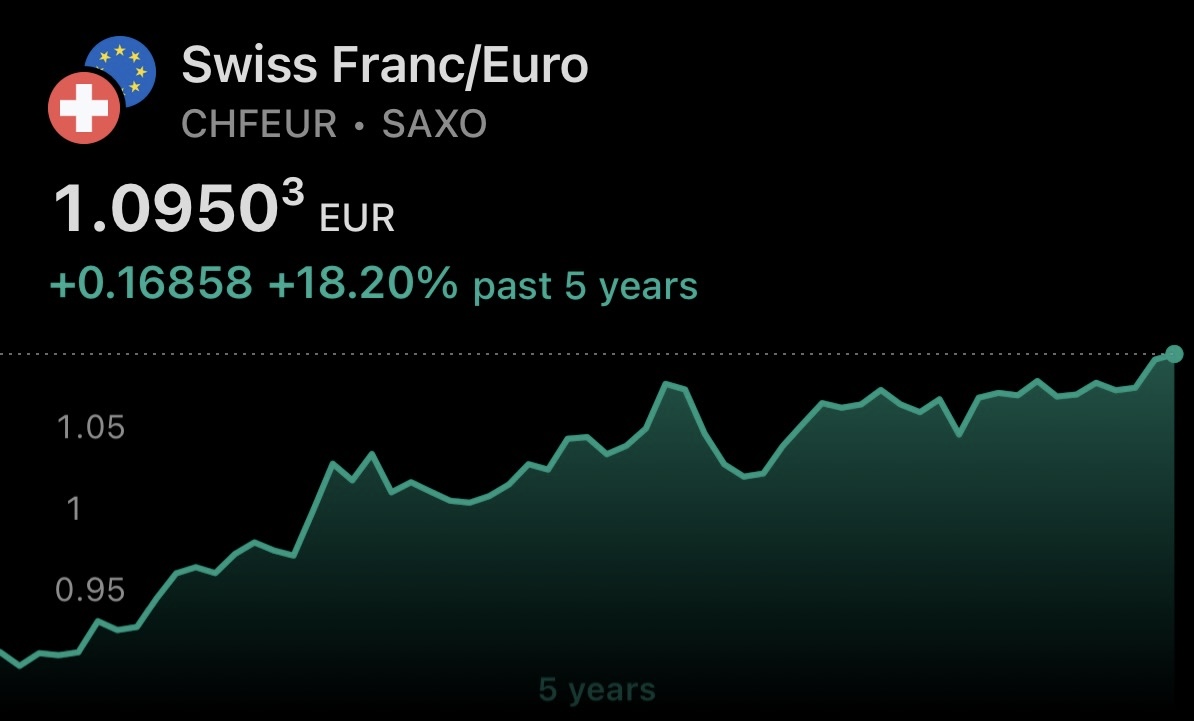
CHF Is Attractive Even At Negative Yield
For those who wonder why it makes sense to hold Swiss Frac, even in times when Swiss government bonds have a negative yield, just take a look at the chart in the image
Scarcity Doesn't Make Bitcoin Better Than Gold
Just because something is more scarce, doesn't mean it's more valuable. The number of existing Picasso paintings is much more scarce than Bitcoin - and that number won't increase.
Would you rather have all of Picasso's paintings or all of the Bitcoin? Or maybe that's a bad example. If you own all of the Bitcoin, it's a big question what will the other market participants value it at -- definitely much below the current prices though.
There's a lot more than you can do with gold than with Bitcoin. In fact, the nodes supporting Bitcoin network use gold in their connectors. Not to mention that you can take down Bitcoin, but you can't take down gold (just cut electricity and/or node subnets).
Moreover, saying that gold is "infinite" is wrong technically and practically. There is a big distinction in the amount of gold existent in the universe and Planet Earth, and the amount of gold that's economically viable to obtain.
If your argument on why Bitcoin is better than gold relies heavily on the scarcity aspect - it's probably a weak argument.
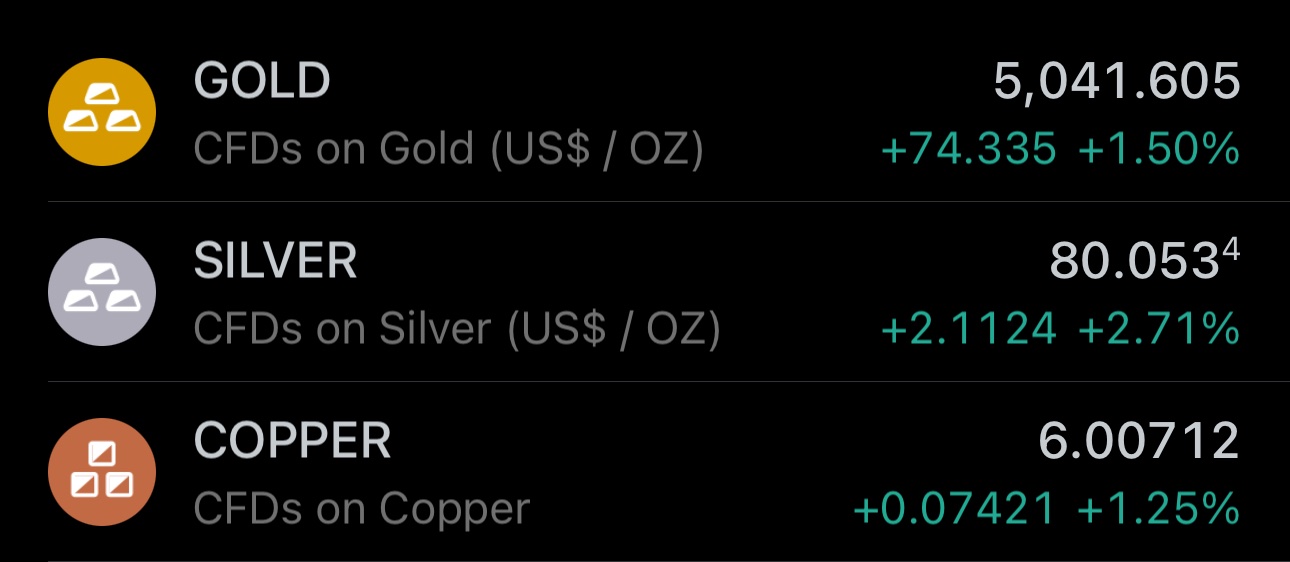
As I've explained in my prior posts: the commodities rally isn't over
Gold is back above $5000
Silver is back above $80
Copper is back above $6
Prices below the above remain a buying opportunity
Enjoy!
It’s literally impossible to compete with calculators
- it doesn’t need breaks or sleep or weekends
- it costs sub minimum wage an hour
It’s hard to make the case to hire quants anymore.
The thing I don’t get is why all the financial companies are hiring so many quants still?
(or you can use an an analogy with autopilot and human pilots to answer this question 😄)
AGI Is Perpetually 6-12 Months Away
Anthropic's CEO warned that software engineers will be obsolete in the next 12 months. But then again, he said the same thing about a year ago 😂
It seems that AI is perpetually 6-12 months away from replacing software engineers.
I don't think that people who spread these claims actually understand how much of a gap AI needs to close for this to happen.
It certainly won't happen in the next year.
Don't Be Fooled By Backtest Performance
I've been coming accross of posts on X from accounts showcasing 70%+ returns when backtesting their vibe-coded trading strategies. Don't be misguidaded by those numbers and claims.
Most likely it performs well on historical data, but is random at best with new data.Agents are not that good at developing profitable trading strategies, as they tend to stick 'default' statistical measures like RSI and hope for the best 😄 If it was that easy - everyone would do it, thus erasing any alpha
These vibe-coded models most likely overfitting
No AGI With LLMs In Their Current Form.
Generative models are just one type of models in ML. Neither self-driving cars, nor inference about financial data primarily rely on generative models. Perhaps you can have LLM program that logic on the go, but that would require the LLM to effectively dominate those tasks (i.e. effectively become good at driving a car and being able to build sound financial models via a programming language), and given the probabilistic nature of the inference I don’t think we can have LLMs and agents fully taking over these critical areas. Regarding the probabilistic nature, I’m specifically referring the unsecured/unparameterized probability - it’s hard to modulate the potential error.
Right now, agent setups are very good at boilerplate, repeatable code - and most of the code is like that. Most of software development is already abstracted by various frameworks, and a lot of the softwares do very similar tasks and are implemented in similar ways, following specific patterns. Anecdotally, think of a generic SaaS - there are several competing products that do basically the same thing, because they solve a common problem. Agents/LLMs are already great at predicting code of which they have a lot of examples in their training set. This alone, is a massive productivity boost, especially if you are prototyping/iterating.
To give a more concrete answer, the current tech would probably top out at multi-agent, multi-model and some form of DSL(s). So you would have multiple agents, some of them using distinct models. For example, one model for planning, another model for writing code, another model for debugging, etc. The DSLs would be used for both: customizing agents and models (input) and the model would output the code in a DSL (output). So when you ask the model to generate code, it would output it in a higher-level programming language/DSL, and then that one would either be compiled down/translated into a different target, wether that is machine code or a programming language like Python. The DSL design would be optimized for this “generative development” - in practice it will make things like math-induced security issues more difficult for LLMs to make (e.g. the DSL forces the LLM to use pre-defined cryptographic primitives, and at compilation time type metadata is associated to enforce its correct usage across schemes). So at this tech’s peak, the LLMs probably won’t be outputting their code in directly Python. I don’t mean that this is the peak for generative models or ML field as a whole, but for the current state of the tech and the approaches it uses.
Before the tech tops out, however, I think there will be a security issue at scale, followed by an increased focus on security of agents and the the inferred code. Since many products will be using the same models to generate code, the same flawed security patterns will arise in many places, and it will be “easy” to exploit them at scale. Even with detailed instructions, SOTA models still generate vulnerabilities. Even though most of the code is fine, it takes one small issue in a sensitive place to compromise the system - and if you write any non-trivial code with LLMs, you will run into them. I’ve encountered a lot of this issues myself, and in the code that I’ve reviewed from other developers who wrote their code with LLMs. Proper context helps a lot, but it doesn’t resolve the probabilistic nature of the output.
Regarding getting closer to human-like functionality, it will almost certainly require other ML schemes/approaches in addition to what we have now and further refining and combination of existing approaches. I think we will soon go into meta-models, where a model internally uses other models/sub models to produce the output (in its simplest form, think of a random forest that “choses” the most appropriate sub-model to run or the output which one of the sub-model’s outputs to use for the next step) - this can help mitigate some of the risks arising from the probabilistic nature of the inference. That would require coordinated, specialized agents, powered by meta-models.
Where I think we have a lot to still to gain with the current tech, even if its progress freezes, is education. LLMs provide a novel way to interact with digital information, you can do it in the same way that you would interact with another human - via spoken language. Being able to formulate your very specific questions, in your very specific way and usually getting a correct answer to it still amazes me to this day. If you combine generative models with VR, you get a whole new dimension of experiencing information, allowing to learn more effectively.
AI will follow a much more logarithmic growth than the hype may lead you to believe
We've been perpetually '6 months away from AGI', yet as amazing the SOTA generative models are - we're no where near that.
I don't believe that the current generative ML architectures will be enough to deliver the promises even over the next decade. Generative models have their limits.
There's also a massive AI bubble in the U.S., wit the same entities over promising on results directly benefiting from public funds, which get counted as revenue many times over. Maybe this need a new term like, rerevenuezation (like rehypothecation with bonds) 😄
With that said, I don't think we're anywhere near the full benefits just from the tech we have available up to today. Agentic systems in particular.
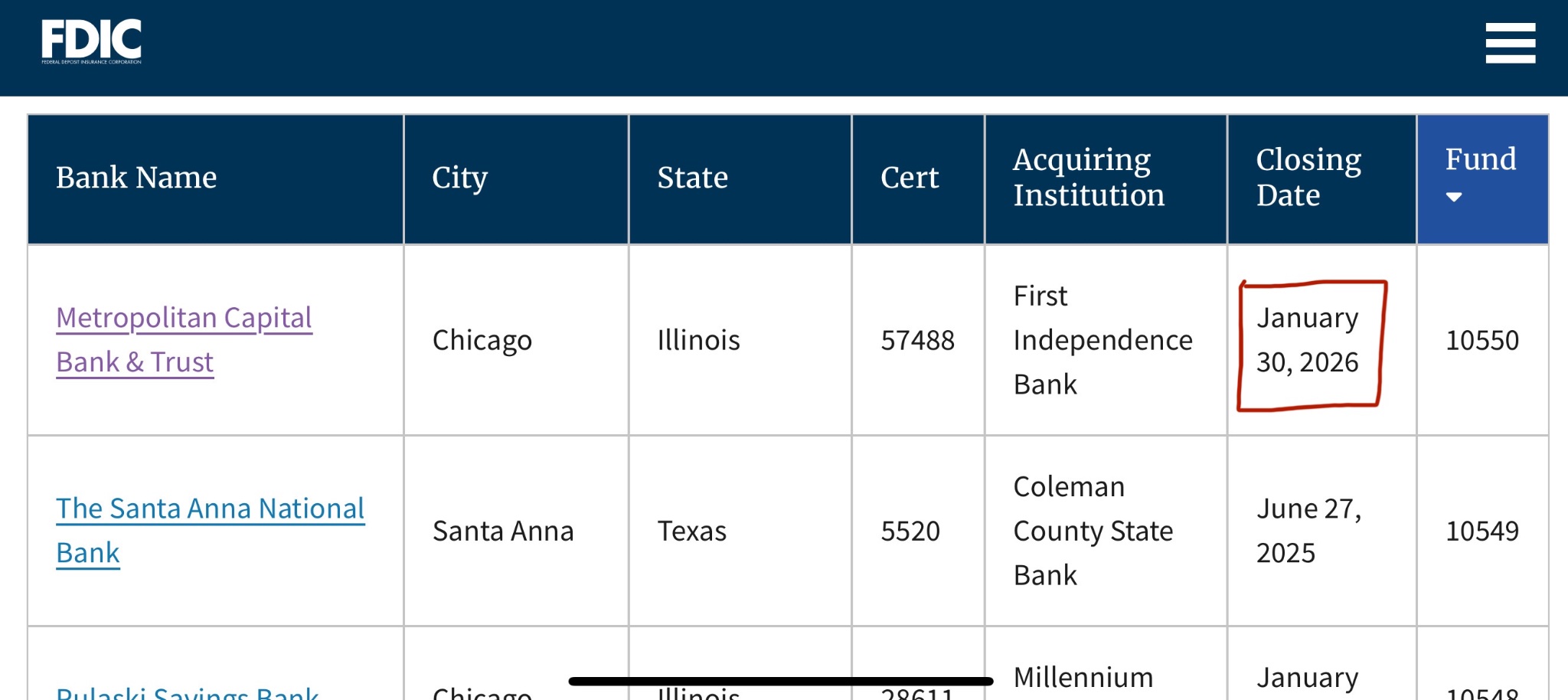
Metropolitan Capital Bank & Trust is the first US bank to fail in 2026
January 30th 2026: Metropolitan Capital Bank & Trust was closed by the Illinois Department of Financial and Professional Regulation, appointing the Federal Deposit Insurance Corporation (FDIC) as the receiver.
The failure is expected to cost the Deposit Insurance Fund (DIF) ≈$20M, but it can changed depending on the price the failed bank's assets are liquidated at.
Back in August 2019 the same bank was formally accused and investigated for unsafe and unsound banking practices by the regulators (FDIC, IDFPR). It was concluded that there were weaknesses in liquidity, solvency, management and asset quality. As a result of that, the bank was forced into a corrective action plan.
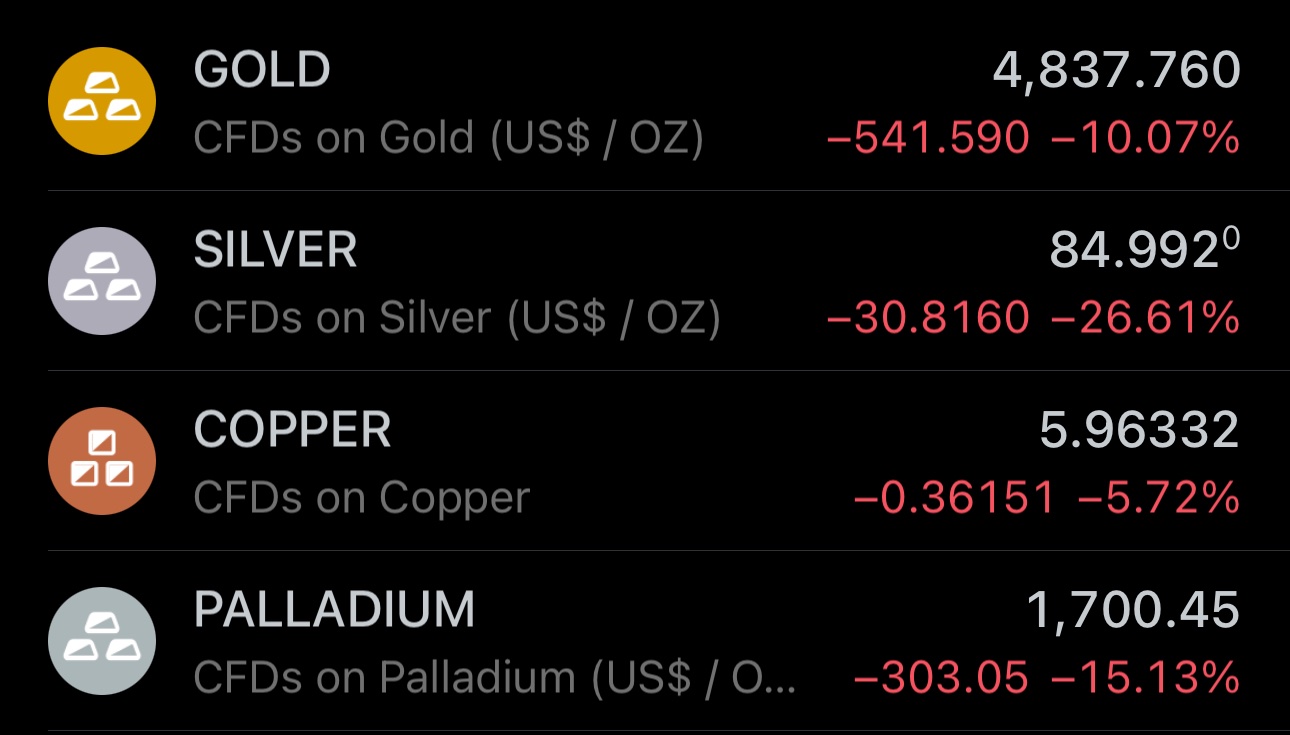
Enjoy the price dip across communities
This is, once again, a buying opportunity

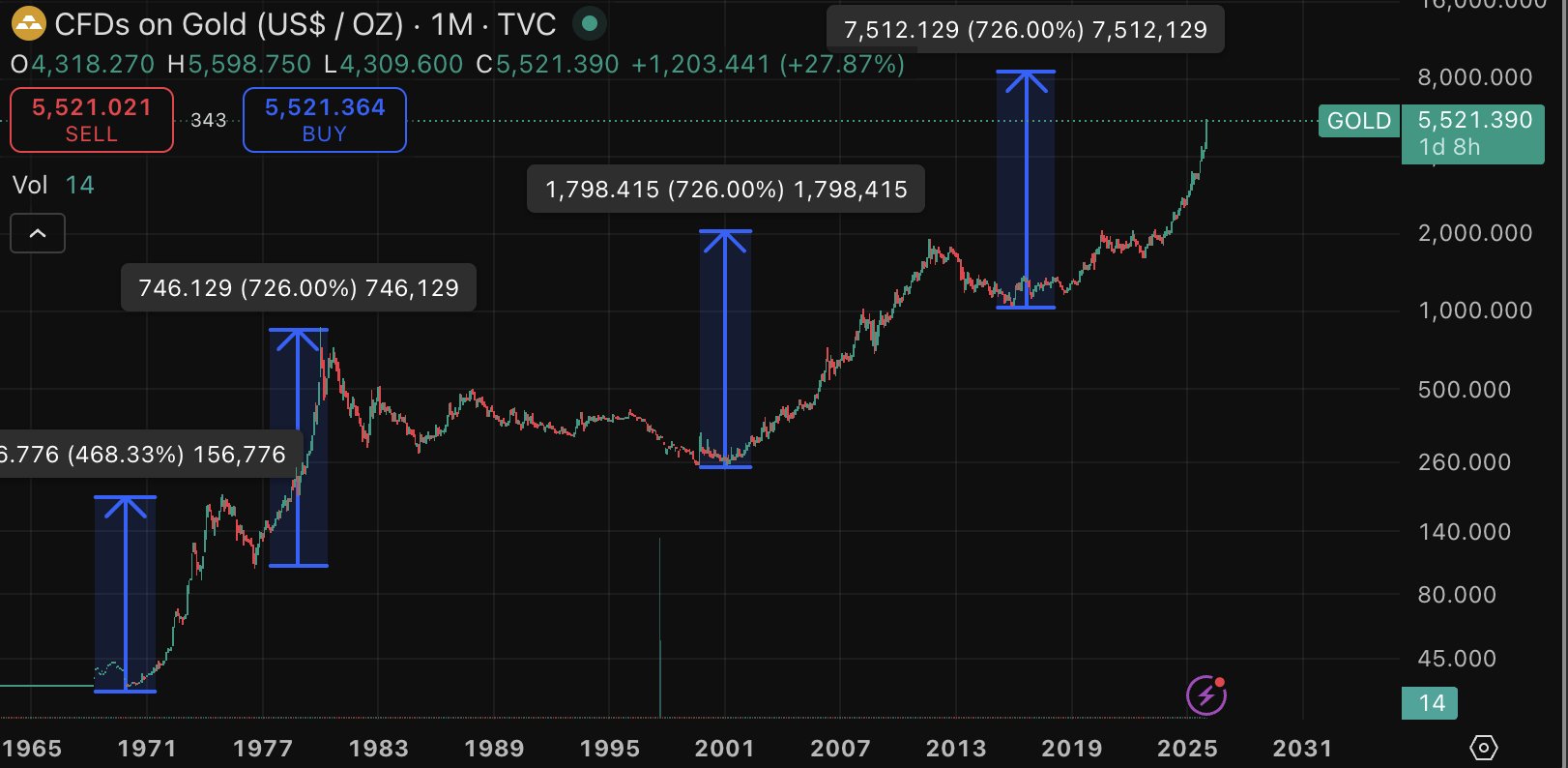
My Target For Gold Is At Least ≈7500 USD Per Ounce
I would like to clarify that this is my *minimum*, medium-to-longterm target for this commodity cycle.
Gold reaching $7500 wouldn't be anything out of the ordinary. It may happen faster than you think.
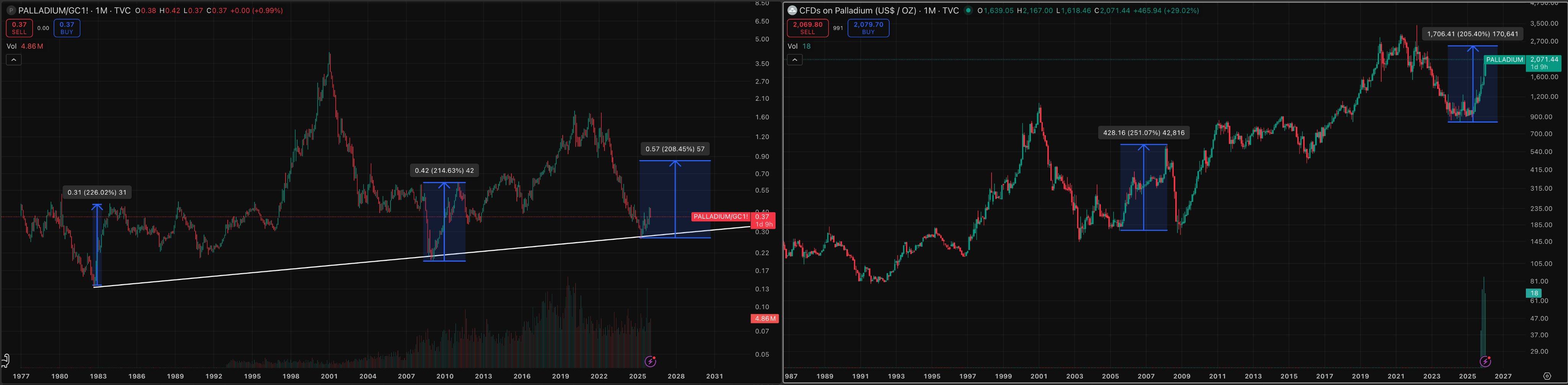
Palladium Is A Great Investment In 2026
Palladium already more than doubled since 2025, but its upwards move won't stop here, as it's setup to appreciate against both, USD and gold.
As I've previously explained, the current commodities supercycle will lead to a price increase across the whole set of commodities, which includes precious and industrial metals and their miners. Palladium is very well positioned for the next leg of liquidity inflow.
Against USD, palladium is currently trading at ≈$2075/oz. My 2026 target for Palladium is at least ≈$2500/oz, or up another ≈24% from current price levels. Platinum has recently rebounded from its monthly support line.
Against gold, palladium is in a similar situation, as its rebounding from a monthly support trend line. The current Palladium/Gold ratio is at ≈0.38. I expect it to rebound upwards to at least ≈0.7, meaning that palladium is setup to appreciate against gold. Even if gold retraces in the short-to-medium term, I don't expect that price drop be to neither permanent, nor long-lasting.
There is also an ongoing deficit of palladium supply relative to its demand.