My Thoughts
Short-form commentary on macro, market structure, commodities, Bitcoin, crypto markets, and AI.

I'll be using PAXG prices as a proxy for gold prices. The great thing about PAXG is that Binance provides for historical 1-minute OCHLV data dating back more than 5 years
My plan is to use this data to derive more signals and/or features for the meta forest
A script is in the process of downloading and preparing the data 😄
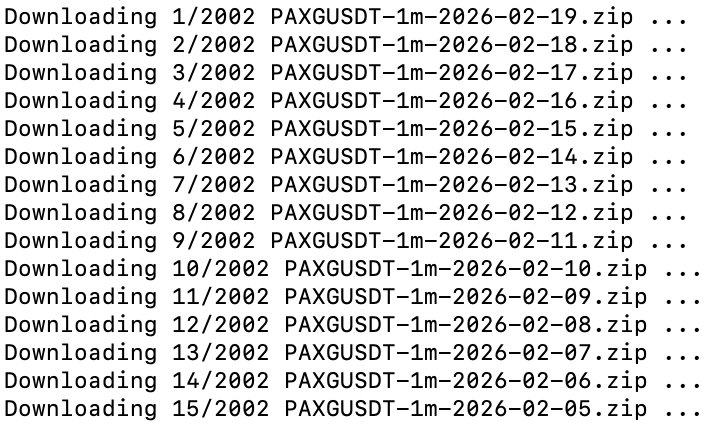
The random forest's features have been heavily refactored. I also replaced the polymarket feature with lookahead bias (the proxy model) with a combination of other indicators.

As a result of the first step in optimizing/prioritizing the random forest’s features -- I've dropped about half of them 😁
As a result of the first step in optimizing/prioritizing the random forest’s features -- I've dropped about half of them 😁
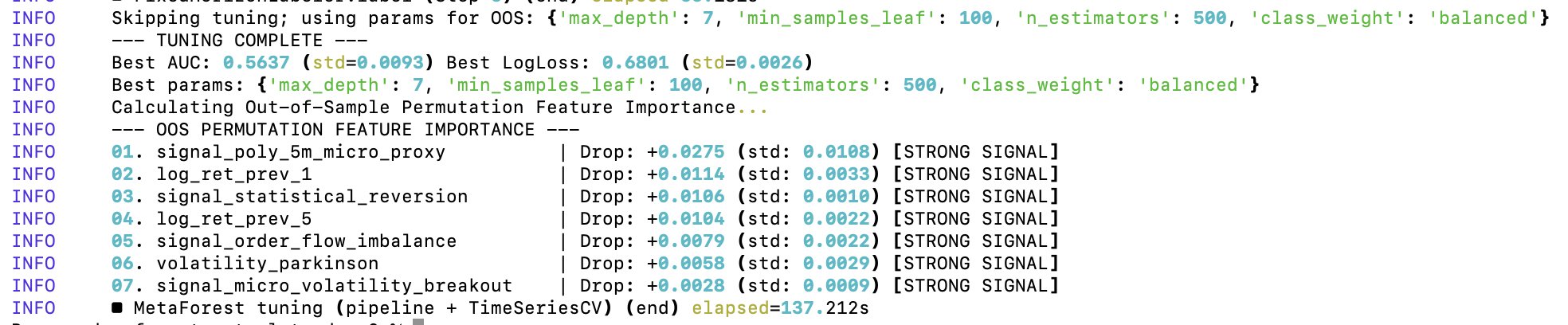
Out of Sample Permutation Feature Importance For Random Forest’s Feature Optimization
After the first level of tuning of the random forest’s parameters, it came time to optimize the features on which the random forest gets trained on. I’ve already did a minor cleanup, but I didn’t yet test for the predictive importance of each feature in the random forest.
To optimize the random forest’s features, I’m using Out of Sample Permutation Feature Importance (OOS). The OOS approach consists in three core steps:
1️⃣ Train the random forest once on the training data
2️⃣ Take out-of-sample validation data (testing data), permute the values of a single feature/values within the same column and pass them to the model trained in step 1.
3️⃣ A feature is important for the model if the model’s predictive power reduces significantly when that feature’s values are randomly shuffled.
The “out of sample” part refers to the fact that the set of data used to train the model and evaluate it after permutations is distinct, thus reducing the contribution of noise to the evaluation metrics. By default, scikit-learn uses Gini Importance to rank features by their utility to the model. Gini is a bad metric for my data because of:
➖ High cardinality bias (it has an inherent bias towards continuous variables, and some of my features are discrete)
➖ Gini importance is computed on the training data
➖ In case of two correlated features, the random forest will randomly pick one at each split, but Gini will actually divide the importance between the two
Additionally, the out-of-sample Area Under the ROC Curve (AUC) of 0.7566 is unrealistically good for predicting 5-minute Bitcoin price moves. This value implies that if you pick a random 5-minute winning window and a 5-minute losing one, my model ranks the winner window ≈76% of the time. Either I found a model that beats virtually every financial institution in existence, or there is a lookahead bias and overfitting happening in the model.
Conclusion: my meta forest — the “seconds_to_settle” feature is basically carrying the entire model 😂 So in its current state, the random forest is training almost entirely on the time of day/time to expiration. The cleanup has started.
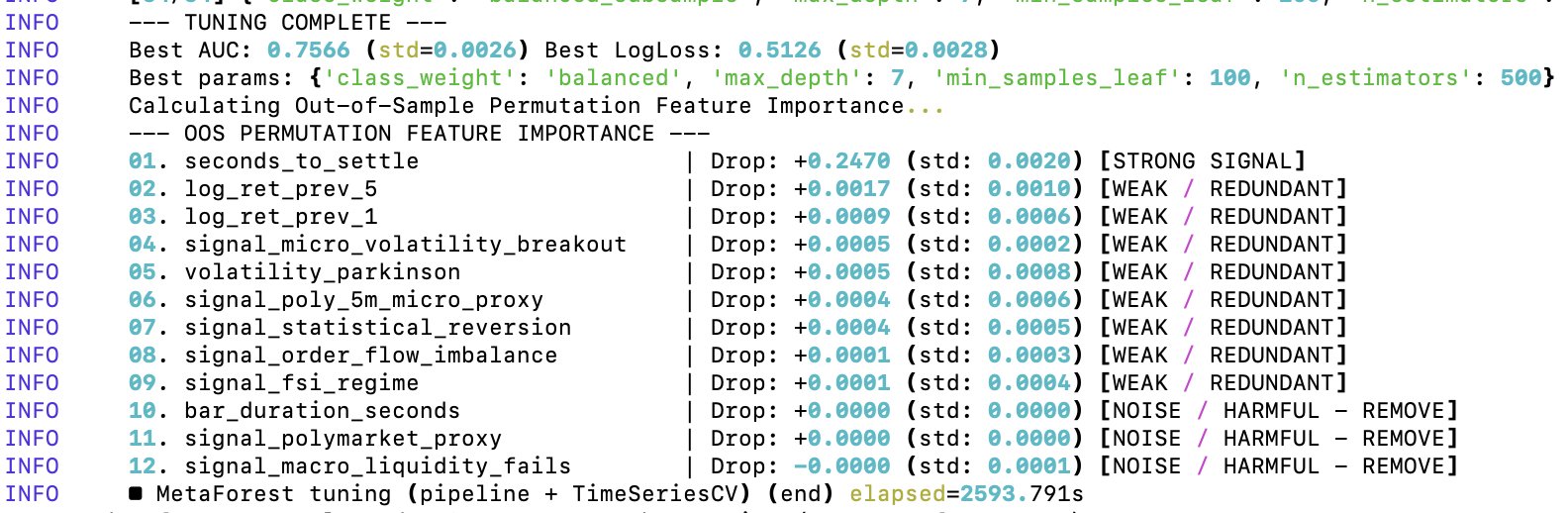
Out of Sample Permutation Feature Importance For Random Forest’s Feature Optimization
After the first level of tuning of the random forest’s parameters, it came time to optimize the features on which the random forest gets trained on. I’ve already did a minor cleanup, but I didn’t yet test for the predictive importance of each feature in the random forest.
To optimize the random forest’s features, I’m using Out of Sample Permutation Feature Importance (OOS). The OOS approach consists in three core steps:
1️⃣ Train the random forest once on the training data
2️⃣ Take out-of-sample validation data (testing data), permute the values of a single feature/values within the same column and pass them to the model trained in step 1.
3️⃣ A feature is important for the model if the model’s predictive power reduces significantly when that feature’s values are randomly shuffled.
The “out of sample” part refers to the fact that the set of data used to train the model and evaluate it after permutations is distinct, thus reducing the contribution of noise to the evaluation metrics. By default, scikit-learn uses Gini Importance to rank features by their utility to the model. Gini is a bad metric for my data because of:
➖ High cardinality bias (it has an inherent bias towards continuous variables, and some of my features are discrete)
➖ Gini importance is computed on the training data
➖ In case of two correlated features, the random forest will randomly pick one at each split, but Gini will actually divide the importance between the two
Additionally, the out-of-sample Area Under the ROC Curve (AUC) of 0.7566 is unrealistically good for predicting 5-minute Bitcoin price moves. This value implies that if you pick a random 5-minute winning window and a 5-minute losing one, my model ranks the winner window ≈76% of the time. Either I found a model that beats virtually every financial institution in existence, or there is a lookahead bias and overfitting happening in the model.
Conclusion: my meta forest — the “seconds_to_settle” feature is basically carrying the entire model 😂 So in its current state, the random forest is training almost entirely on the time of day/time to expiration. The cleanup has started.
The time to optimize hyperparameters of the random forest has come
Starting with a grid search approach

The model's first live data trade was a successful Bitcoin short! The position was open for 4 minutes, for a 0.11% return

Added a connection to Binance's futures API and now I have the base learners and the random forest looking for profitable 5-minute Bitcoin trades in real time
Let's see how it goes, the model already entered its first trade. Let's see how it goes 😄

This a gross oversimplification of what it takes to replicate the human brain with AI
The post is assuming we have a model that can accurately replicate the human brain, which we don't.
200T parameter models won't solve that -- you'll still have a high model bias.
Vibe-Coding Vulnerabilities With Claude Code
A decade ago there was a joke that IoT stands for "Internet of Vulnerabilities", given how vulnerable many Internet of Things devices were and how easy it was to exploit them.
I think we will enter an even bigger era of vulnerabilities with vibe-coded systems, especially with agents handling everything from feature development to deployment. You are outsourcing the security of your product/application to a probabilistic mathematical model, which hallucinates by design.
For a sufficiently complex system, it's not a question of IF but of WHEN the LLM will make a security-compromising mistake. Unfortunately, large customer data leaks may become the norm.
If you care about the secrecy of your data, I would advise you be very wary of products developed in such manner. Of course, for many use cases you may also not care about this, and prioritize lower cost or specific features. But you must be aware of the risks.
You are essentially one prompt away from compromising your system and its data. We will probably even have new laws/regulations coming out to address this.
Proxy Model From Polymarket's 15 Minute Bitcoin Price
I found historical datasets for Polymarket's 15 minute up or down Bitcoin price and I think I can use this data to obtain useful signals via a proxy model. I'll start with linear regression to build a prediction model, to see if this transfer learning approach works here.
Yes, it will be overfitting, but for this signal generator it would be by design. The end goal is to find features that improve the random forest's split rules, thus further improving the win rate.
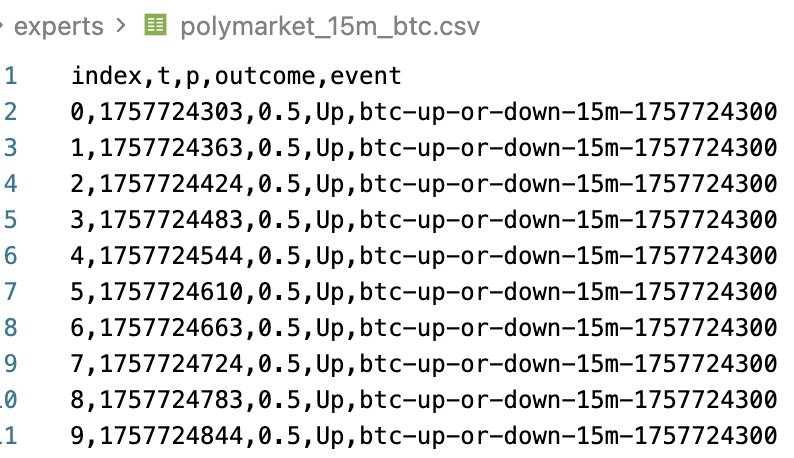
Primary Dealers Failures To Settle Implications For Risk Assets
Security settlement failures on the dealer side are a signal of liquidity stress. In short, it signals that either collateral (securities) or USD liquidity are short. Generally, this is bearish for risk assets.
Dealers exercise a key liquidity role in the financial markets microstructure, so a significant stress on their operations will propagate throughout the market.
You can anecdotally visualize this correlation in Bitcoin by noticing that the peaks of failures to receive/deliver by dealers coincide with at least short-term tops for Bitcoin prices.
This weekly set of data is made freely available by Office of Financial Research (OFR), and you can download it CSV or JSON formats. If you are incorporating this data into your machine-learning trading models, beware of the look-ahead bias, as this OFR data is released with about a week of delay.
After tweaking the existing set of base learner models, the random-forest driven trading model factory continues to improve
The win rate for predicting Bitcoin's 5-minute price moves (binary) is now approaching 54%. A win rate of ≈56% should suffice to accommodate for transaction costs. Win rates over 60% is where it starts to get interesting.

If you invested just $100 in Gold in 4000 BCE, today it would be worth $100
This is because USD didn't exist 6000 years ago, so it wouldn't be accepted as means of settlement in Ancient Egypt, thus you wouldn't find a counterparty willing to sell you gold in exchange for US currency.
6000 years is also for how long gold has been used as money. Yet, some still believe that Bitcoin is the new gold and that it will replace gold as money 😄
Expert optimization is going well, and I'm starting to move towards the alpha in 5-minute Bitcoin price markets
I'm not claiming that the model that I currently have is meaningful (it's NOT!), but it's getting closer to interesting win rate ratios (>55%)

Currently, this is the most valued expert in my model factory pipeline
Not because it does anything useful, but precisely because it does not
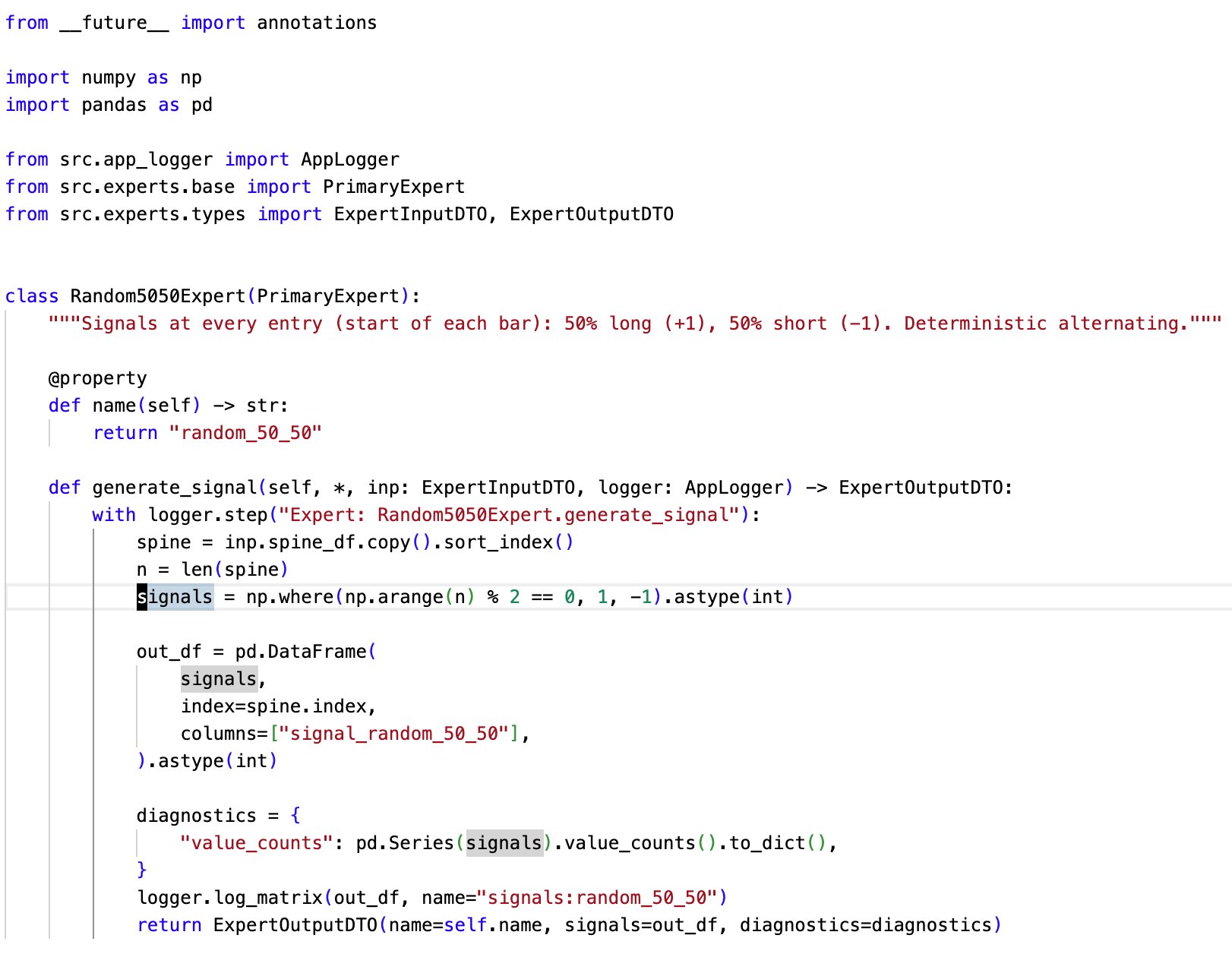
The expert randomly emits positive(buy) or negative(sell) signals. This is a rough baseline for random behaviour. Very useful for the integration testing of the pipeline and identifying noise
My random forest looks much better after the clean-up
The feature matrix has been refactored to only include features from which the random forest will be able to learn more effectively. This should greatly reduce the noise
Now, it's time to optimize signals 😄

My ML model factory produced this amazing model that trades Bitcoin on 5-minute intervals, cut off at each 5th minute (very similar to Polymarket's 5 minute BTC markets) and it made over 200K trades in ≈7 months
Stats:
- 200K trades
- 6.69% profit
- 49% win rate
So I've pretty much discovered a coin flip 🤣

They say that AI agents will replace all white collar-jobs in the next 6-12 months 😄
So LLMs only have 5-11 months to learn about car washing.
This simple prompt breaks ChatGPT, DeepSeek, Qwen and Kimi. Works on Gemini though.
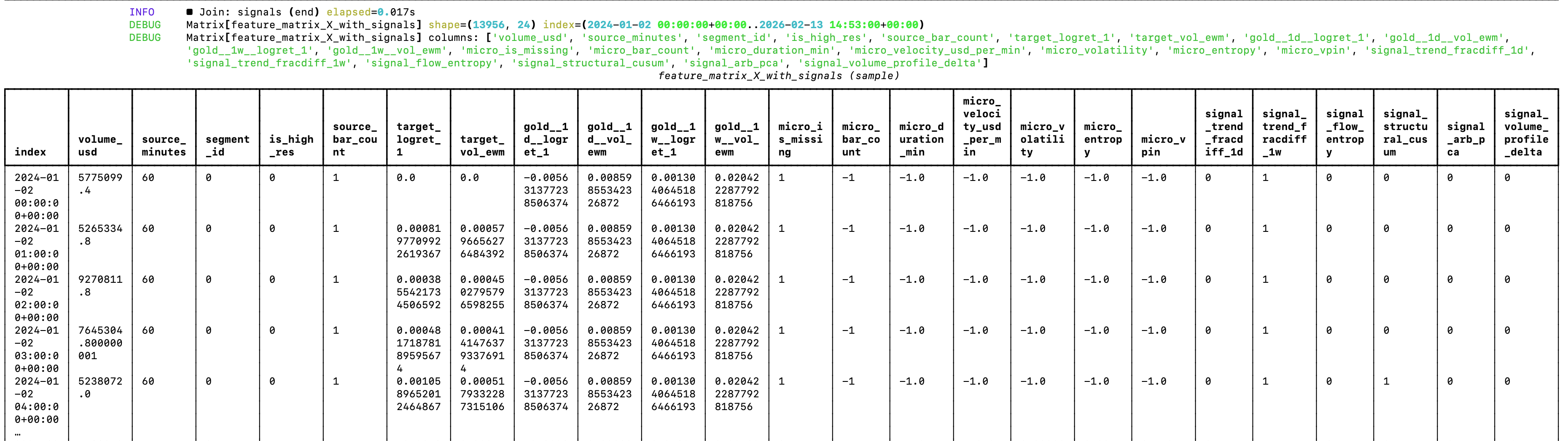
The random forest that guides my model factory needs refactoring
While the current architecture shows good prospects for generating profitable trading models, the random forest is currently a bit of a mess 😅 If you look at the image attached to the post, you can see why.
Since the random forest can’t extrapolate, features like the date and source segment will just make the forest learn on noise (it will train on association between those features, e.g. it’s not very useful to learn that volume in 2025 was higher than in 2024). But this was expected. The goal was to validate an architectural approach that could work. Now it’s time for optimizations and changes. Actually, changes before optimizations.
Another thing that I’ll get rid of is the hybrid spine for supporting data from multiple timeframes, as the model didn’t extract any meaningful alpha — and some of it has even confused the random forest. I’m sure there is way to make even with limited data, but I’ll be moving to testing it on dataset for which I have access to highly granular data (hello, Bitcoin!). So the logic of the data loader in the pipeline will be greatly simplified.
I’ll also make the labeler configurable, so that you can use the same set of features for different types of predictions. For example, you could have the “unconstrained” standard deviation labelling in the sense hat you can enter and exit the position at any time, to constrained logic scenarios such as the ones of Polymarket’s 5-minute price predictions on Bitcoin, where you can only enter a position at specific times, and the resolution happens at specific times (e.g. at the end of every 5th minute of the day, starting from 0).
The core logic of the ML pipeline remans the same.
China Banned Gold & Silver As Money In 1983
While it remained legal to hold gold as an individual in PRC, you couldn't:
- Use gold/silver as money (unit of account/pricing)
- Trade gold/silver privately (you could only sell it to PBoC)
- Lend or pledge (use as collateral) gold/silver
- Act as a dealer of gold, unless authorized by PBoC
So effectively, as an individual in PRC, you could only sell your gold & silver through the PBoC system, but it was fully lawful to own those metals. Only if you violated the rules above, authorities could force you to liquidate your gold to PBoC at a discount over the spot price.
This is a big contrast with the gold ban in the United States via Executive Order 6102 in 1933, which required all persons to surrender/liquidate their gold coins, bullion and certificates to the state. Moreover, in 1933 the U.S. government credited you $20.67 per oz gold that you surrender. About a year later, the same government that forced people to liquidate their gold at $20.67, proceeded to raise the price of gold to $35 per oz (at that time the price of the gold was fixed by the government, not determined by market price action like today). So the U.S. government made an instant ≈70% profit on the public's gold.

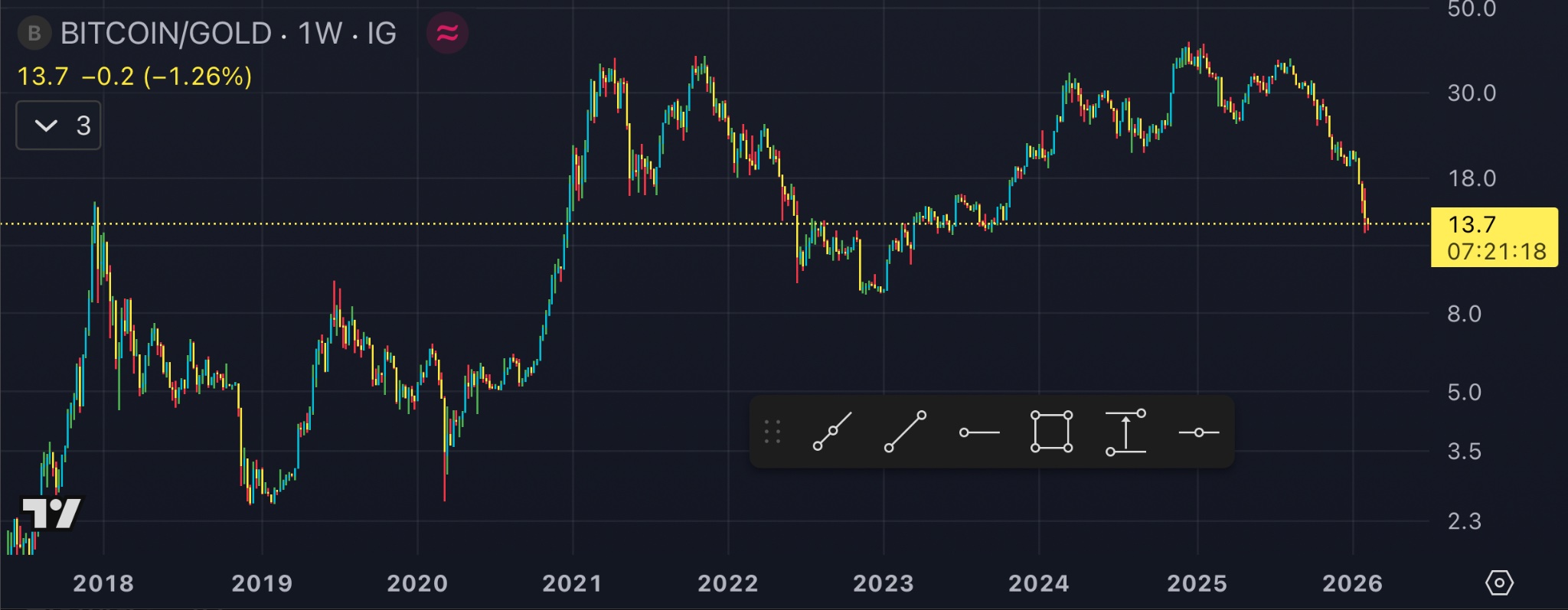
Gold Outperformed Bitcoin In The Last 8 Years
Let's go back in time. It's December 2017. You have $1000 to invest, and you have 2 options: gold or Bitcoin. Which one would you choose?
If you bought $1000 worth of BTC at ≈$20K/BTC in December 2017, you'd now have ≈$3500, or roughly a $2500 net profit.
If you instead bought $1000 worth of gold at ≈$1260/oz, you'd now have ≈$4000, or roughly $3000 net profit.
And throughout those 8 years of holding, gold's price never crashed by ≈50%, like it's more or less the norm with Bitcoin & rest of the crypto.
Bitcoin can be a great idea for your portfolio, but if you're so determined to HODL long-term, you may be much better off with gold.
My wife and I met the charging bull himself
He confirmed that he's heading towards commodities

China Also Banned Gold & Silver In 1983
But unlike in 1933 in the U.S., there was no global ban on the public owning gold & silver. The public was however not allowed to use it as money, collateral, lend it or trade it. Everything gold/silver related had to go through PBoC.
I'll cover this in more detail in a future post.

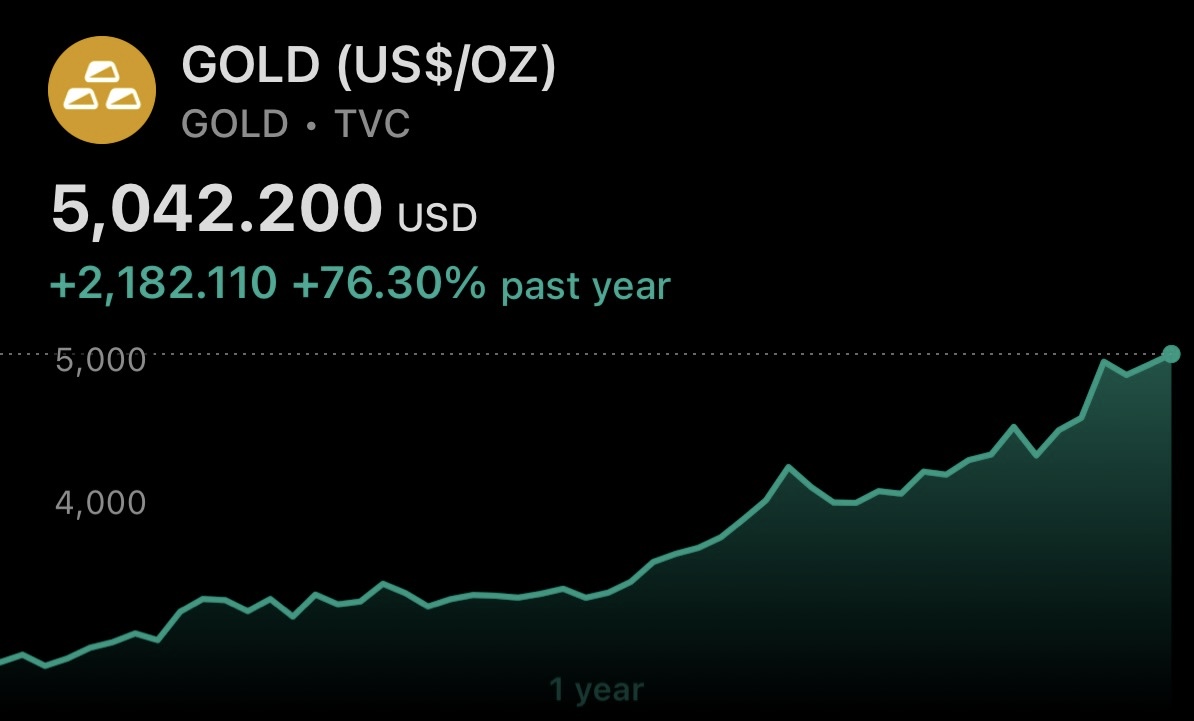
In 1934, the U.S. government had to legally raise the price of gold to make a ≈70% profit on it in ≈1 year
Today, gold goes up by more than 70%/year just by market forces 😄
I've been spamming you to buy gold since it was ≈$1800/oz
How USA Profited 70% On Gold In 1 Year
In 1933, the U.S. government purchased gold at $20.67/oz. In 1934, gold was valued at $35/oz, or ≈70% higher!
How did they do it? Easy:
1️⃣ Force public to liquidate gold at $20.67/oz
2️⃣ Raise the official gold price to $35/oz
3️⃣ Instant 70% profit 😄
Had the United States citizens not surrendered their gold in 1933 (which would be illegal to do!), they would be 70% richer just a year later. Instead, that wealth was forcefully transferred to the government, and the people who surrendered their gold became 40% poorer just a year later.
